Sentient Agent Bundle Resources
SABR is a system architecture that enables data transformation through deployment and management of AI algorithms in the data center, cloud and at the semi-connected edge.
Introduction
As edge devices become more capable to process data at the edge–including AI inference, data normalizations, encryption, and compression—organizations are looking at new operating models to drive decision-making closer to where data is generated and collected. The objective of this white paper is to articulate the architecture and design of a distributed data stream framework utilized to process large volumes of data across a heterogeneous semi-connected ecosystem of edge devices, named sentient agent bundle resources (SABR).
Problem Statement
Edge Computing brings with it new challenges that solutions in the data center or the cloud only do not have. Many organizations are faced with edge ecosystems that operating in a denied, degraded, intermittent, or limited (DDIL) network environment requiring systems that can work autonomously when network connectivity is in question. Additionally, problems with heterogeneous hardware and software platforms, large volume of data generation and movement, and physical and cyber security make managing applications and devices at the edge complex. So complex that the industry as a whole are behind the projected adoption of the edge computing.
Another technology with promises of opening up new use cases and unlocking data power to accelerate decision-making is artificial intelligence (AI). Moving AI to the edge accelerates decision-making by decreasing the volume of data movement, and moves decision-making close to data generation. Because of the heterogeneity of edge computing, AI models are just as diverse as the types of edge devices. Organizations require a mechanism to manage heterogeneous AI models, their data sources and approaches in a unified manner across a distributed ecosystem.
Organizations need a solution that provide:
- Security – Provides a hardware root of trust to match AI models with attested hardware to prevent AI models from working outside the attested ecosystem. Also prevents unverified and unattested models from running in the ecosystem.
- Manageability – AI models and algorithms are managed from a federated control plane that manages deployment, updates and decommissioning.
- Auditability – Changes to SAPRs, their AI models and algorithms are tracked from a single management framework that can be audited.
- Visibility – Operator awareness of SAPR health, AI model deployments and operational efficiency is enabled.
- Reliability – Because the Learning Corpus is distributed across the ecosystem, there is no single point of failure; operational availability is sustained.
- Resiliency – The SAPRs are designed to run in a DDIL environment; the Learning Corpus takes advantage of this built-in resiliency.
- Consistency – AI model consistency is essential in a mission critical distributed ecosystem. This approach manages AI model divergence by keeping track of SAPRs and AI models in use.
- Simplification – The framework provides resiliency, consistency, reliability and security that all AI algorithms require under DDIL conditions during Distributed Maritime Operations. This simplification enables AI developers to focus on the AI application, not on the complex environment.
- Scalability – System nodes can be added or removed easily without shutting down or reconfiguring the system. Streams and algorithms can also be easily scaled.
Concepts
The Sentient Agent Bundle Resource (SABR) provides an architecture that utilizes well-known concepts and design patterns to enable a resilient, easy-to-use architecture.
The SABR architecture leverages well known design patterns to develop a highly adaptable framework to handle changing requirements. Additionally the SABR solution focuses on ease of use, deployment and maintance of applications, AI models, and micro-services. The execution footprint of SABR must be small < 100 MB to fit on most x86 platforms and take advantange of more advanced processing technologies like GPUs, NPUs, VPUs, and custom ASCIs.
The following design patterns are leveraged in the SABR architecture.
The data stream concept, container bundling in DevSecOps , container sidecar pattern, zero trust architecture, and reinforced collective learning.
Data Stream Concept
The data stream is a mature concept that allows data to be passed between a producer and a set of consumers without direct coupling between the entities. This concept provides the ability to deploy large numbers of producers and consumers in the same ecosystem without the fragility of coupling.
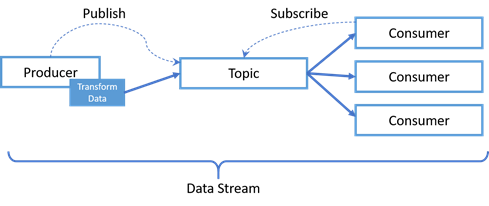
A data stream is created when a producer (a service on a server) publishes data to a topic. One or more consumers subscribe to a topic and are notified when data is published to the topic. The combination of the producer, the topic and the consumers create a data stream. Streams also contain a mechanism, called stream functions, to transform data before it is published to the topic. These functions can also be utilized to identify event conditions and enable controls on stream management to subscribers for capabilities such as access, routing, event driven alerts and data prioritization. Data streams have the benefit of loosely coupling the producer and consumer through an abstraction contained in the PubSub framework. This enables the producer and consumer to operate independent of each other. This is beneficial during intermittent communication conditions since the consumer can continue to operate even when not receiving data from the producer. Another benefit is the producer can cache data if required and send later. For example, if a Submarine is operating at depth, the producer will cache the data and, when re-connected, publish data on the topic again.
Before a producer publishes the data, it uses a transformation algorithm to simplify or aggregate the data. These transformation algorithms can perform any number of functions, including normalization, temporal compression, AI object detection, data aggregation and others. These transformations are invaluable to getting the most effective insight information to the right consumers (decision makers) at the right time.
Managing these data streams, their interactions and transformation algorithms can be difficult without a common framework. There are both open source and commercial stream managers available that can manage the data streams across multiple locations, states of connectivity, and hardware platforms.
Benefits
This concept provides several key benefits for the highly distributed semi-connected environment.
- Dynamic heterogeneous mesh configurations.
- One or more consumers can subscribe to a topic fostering reuse of common producers.
- A consumer can also choose only to consume data when a specific event occurs in a Data Stream.
- Resiliency when the network is down because a producer caches the data and, when re-connected, publish data on the topic again.
Container Bundling in DevSecOps
Traditional DevSecOps pipeline push artifacts a development, build, test, and deploy pipeline that produces and executable that is deployed into production environments. The container ecosystem has made the development of highly portable executables a reality by building container images that can contain several artifacts required to configuraption, secure, and execute microservices in any environment.
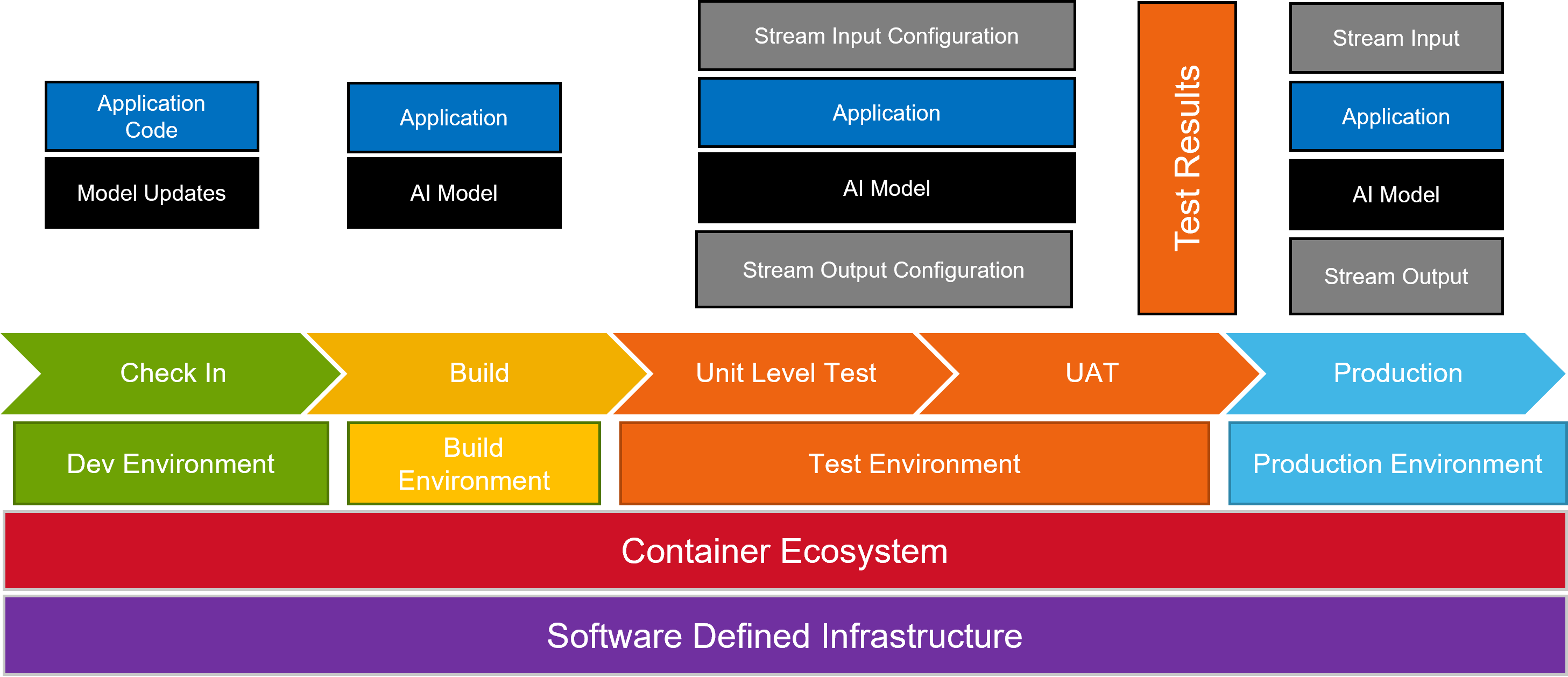
In the case of data streams the DevSecOps pipeline is utilized to bundle the application, the AI Model or data transformation configurations, and the input & output stream configurations. This bundling of all aspects of the data stream provides a mechanism to deploy producers and consumers of data streams anywhere in the edge ecosystem containers can be deployed. The name of these data transformation applications are sentient agent bundles (SAB).
Benefits
This concepts provides several vital benefits to deploy data streams across a distributed environment.
- Standard development and deployment of capabilities across a heterogeneous ecosystem.
- Portability of solutions from in the datacenter into the edge devices.
- Decreased bandwidth to deploy only changes to bundles.
- Speed to deploy capabilities into the ecosystem.
Sentient Agent Bundle (Application Bundle)
The Sentient Agent Bundle (SAB) is an implementation of the container bundle pattern that contains all of the information required to launch all of the microservices, stream definitions, and network configurations needed to run a data transformation algorithm (transformation, ai, analytics) on any node in the ecosystem. The pattern allows a bundle to be deployed on the edge, cloud, or data center securely. When a bundle has been verified and attested, it is unpackaged and deployed to the target node, launching all of the microservices and connecting them to the underlying stream management system.
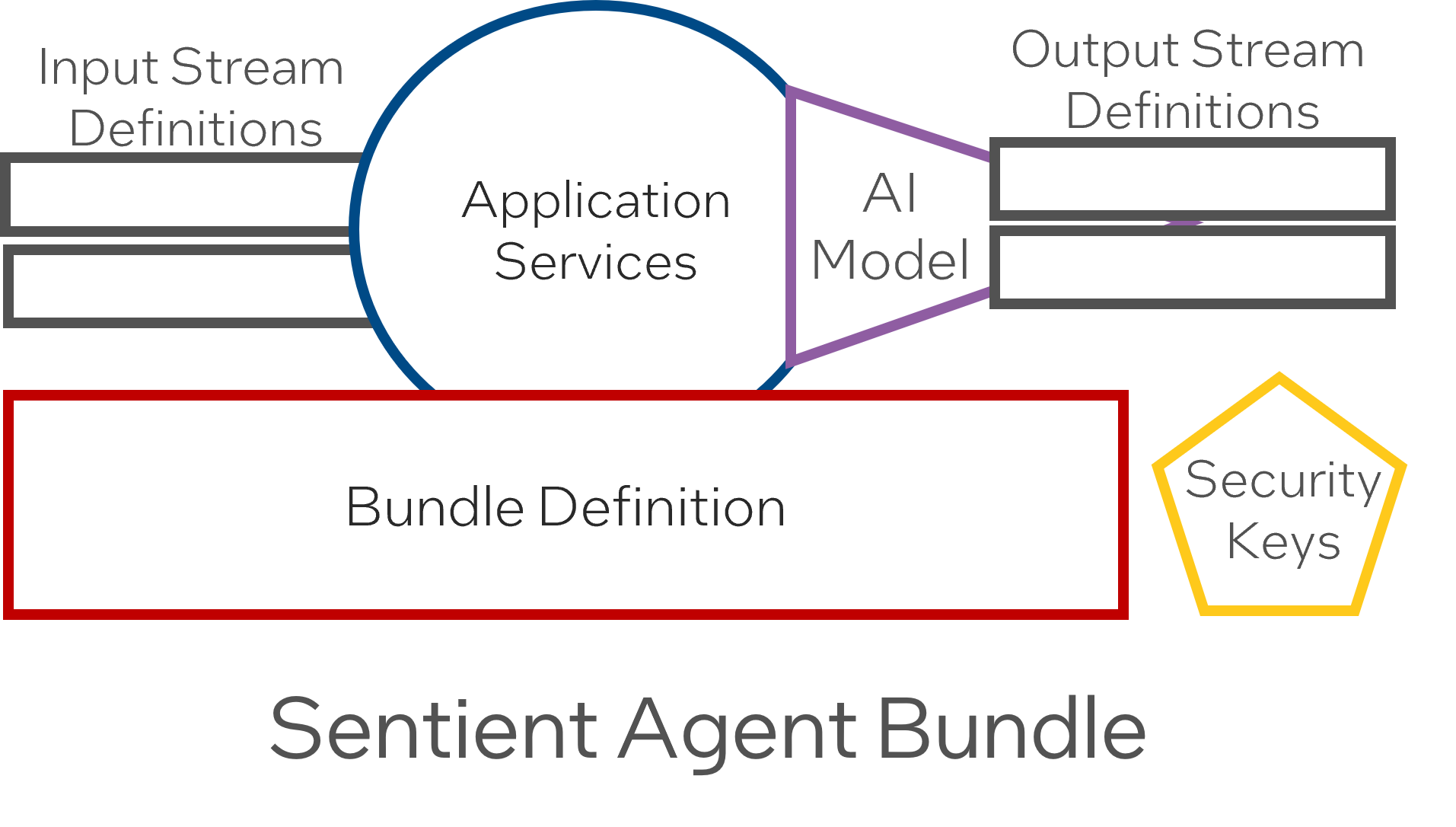
- Sentient Agent Bundle Resources (Agent Bundle) manage transformation algorithms, data stream definitions, and interactions between systems.
- The container ecosystem (including Docker and Kubernetes) and DevOps environments (Red Hat OpenShift and Jenk ins) build and distribute SABRs to Docker swarms K8s clusters.
- The combination of all executables (applications and services), configuration files, stream definitions, data schemas, and transformation algorithms is called a Sentient Agent Bundle Definition (SABD).
- An SABD is represented as one container image in the Docker and K8s ecosystem and is deployed to a processor to bring it into the Learning Corpus mesh architecture.
- A security hash is added to the security keys in the Package and used to notarize the container image in a deployment repository.
Container Sidecar Pattern
A sidecar container is a helper container that helps manage administrative, logging, audit, or security tasks. The sidecar is typically a small container that does specific activities to support the main container. Many organizations use sidecar containers to add consistent behavior across a heterogeneous containers like logging, audit, network encryption, and security.
Sentient Agent Bundle Resource Details (SABR)
While a Sentient Agent Bundle(SAB) contains the definition of a sentient agent, a Sentient Agent Bundle Resources (SABR) is a running instance of an intelligent agent. It includes all the resources that enable the sentient agent to perform all the work designated for the agent. This includes evaluating the bundle against system policies for stream and channel definitions, establishing security domains, and establishing managing streams named LearningIn and LearningOut Streams for each bundle.
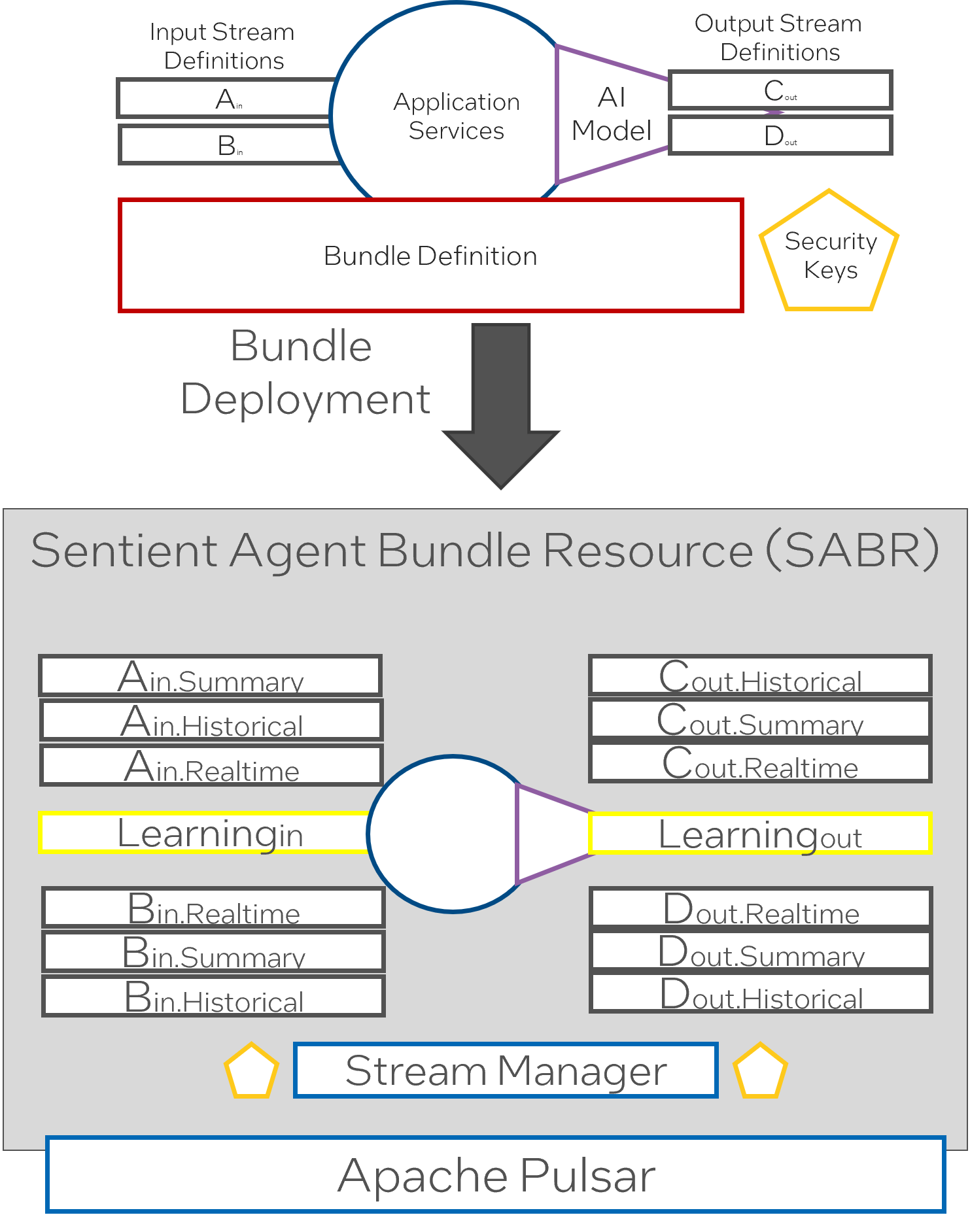
- The Stream Manager creates the channels for each stream and monitors the streams.
- An Learning Stream is created to connect to the learning corpus. Input and Output.
- For each stream definition, there are channels created for each mode of operation. Example: Historical, Summary, Realtime
- Modes of operation are defined for all the applications, and the stream manager handles which channels to use during different modes of operation.
- Streams are encrypted and decrypted using hashes in the security keys.
SABR Deployment
A SABR container contains the stream definitions, security keys, application definitions, AI models, and transformation algorithms. When a SABR is deployed, it explodes the configuration and deploys as many containers as needed to run the SABR and configures the data stream manager to handle the streams and channels based on the system’s policies. All communication to and from the application happens through the channels established in the stream manager.
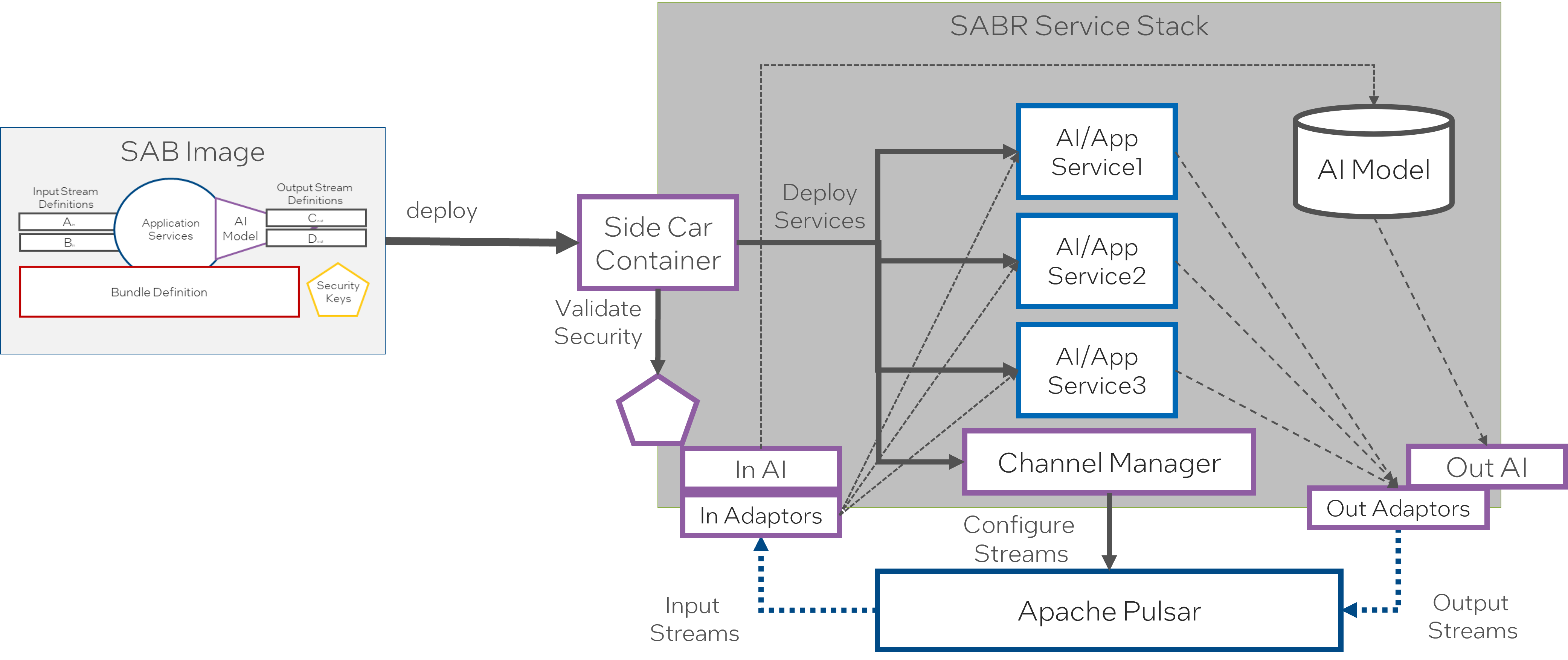
In this case the side car container unpacks all the elements for the sentient agent including one or more microservices, data volumes that includ AI Models, a stream manager micro-service, any input and output stream adaptors required to convert stream data to be ingested by the intelligent agent services, and validates the security certifications to run and decrypt data streams.
Zero Trust Security
In order to secure the network of data streams a security vault is included in the SAB that contains keys, and hashes to establish root of trust between the SABR and the hardware it is running, the consumers of data streams and the producers of data streams.
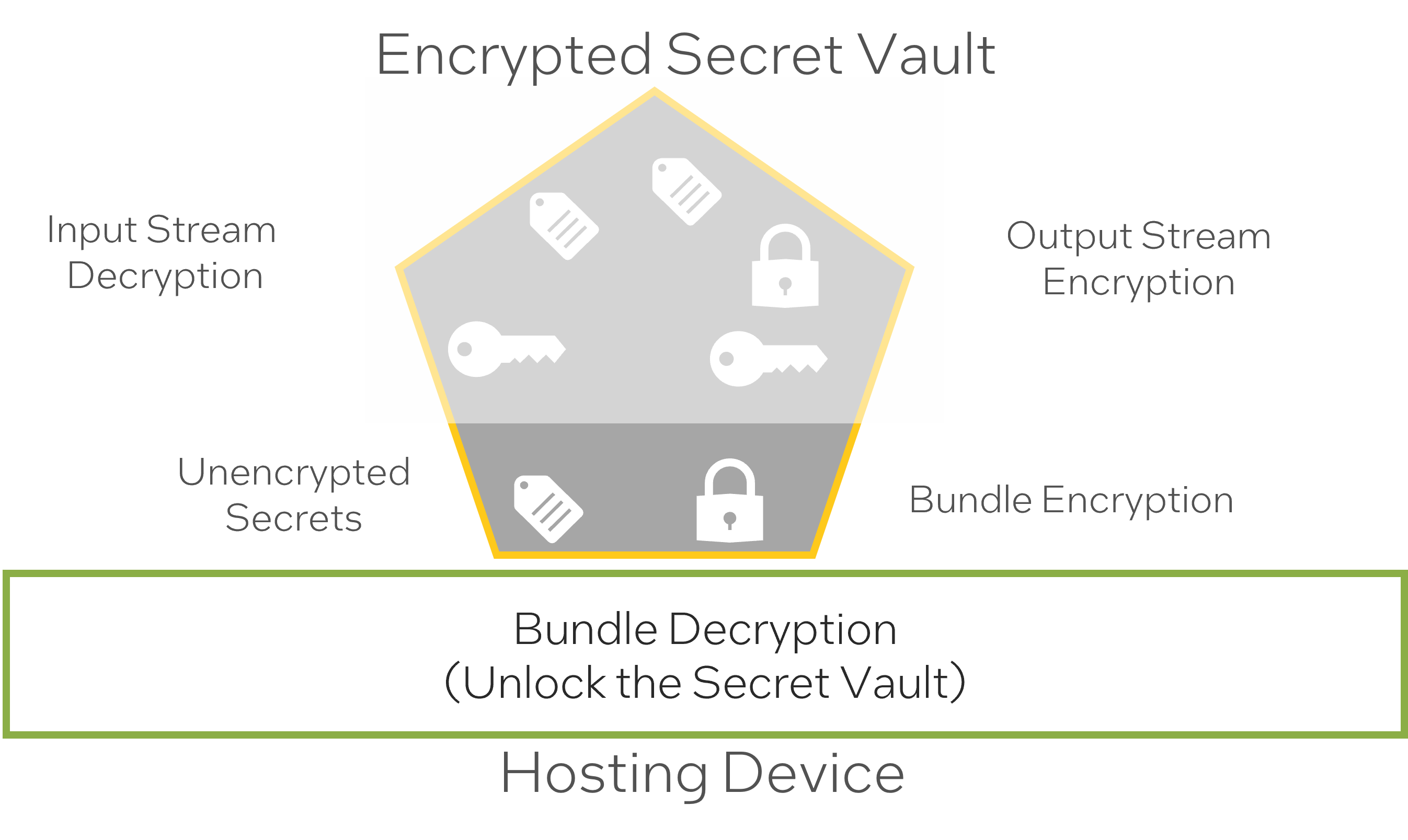
There are four areas of that must be protected inorder to establish a zero trust architecture of data streams.
- Prevent SABRs from running on untrusted edge devices. This prevents a bad actor from aqcuiring a SABR container and running it on their own hardware.
- Prevent untrusted/spoofed SABRs from running on trusted hardware. This prevents bad actors from deploying SABRs into a protected ecosystem, causing havoc or stealing information.
- Prevent publishing of untrusted data onto a data stream. All data stream data is encrypted with appropriate shared encryption keys and hashes.
- Prevent receiving untrusted data from a data stream. Shared and private decryption keys and hashes are available to decrypt input data streams.
- Prevent bad actors from listening into data streams. All data streams are encrypted. All decryption and encryption keys specific to the data stream definitions in the bundle are contained in the secret vault which is encrypted.
- Authorization and access to the data streams is timebase and must be re-attested after the timeout.
The security keys contains two sections and encryption secret vault and an unencrypted security key section. When a SABR is deployed to edge hardware the security keys in the unencrypted section are used to validate and decrypt the bundle including the encrypted secret vault which should be stored in protected memory, not permenately on the device. The keys and hashes stored in the encrypted secret vault decrypt and encrypt the input and output data streams.
Reinforced Collective Learning
In highly dynamic environments, AI models need to change. As AI nodes interact with the real world and are guided by human feedback, the AI models change and adapt to produce better outcomes. As this new information becomes available, the ability to update AI models at the edge is critical. Sharing learnings through propagation of models changes is critical in building a collective intelligent corpus that all edge nodes can leverage to perform their work. Propagating changes to AI models across both static and dynamic training of AI models are essential to heterogeneous platforms that include multiple edge and data center nodes.
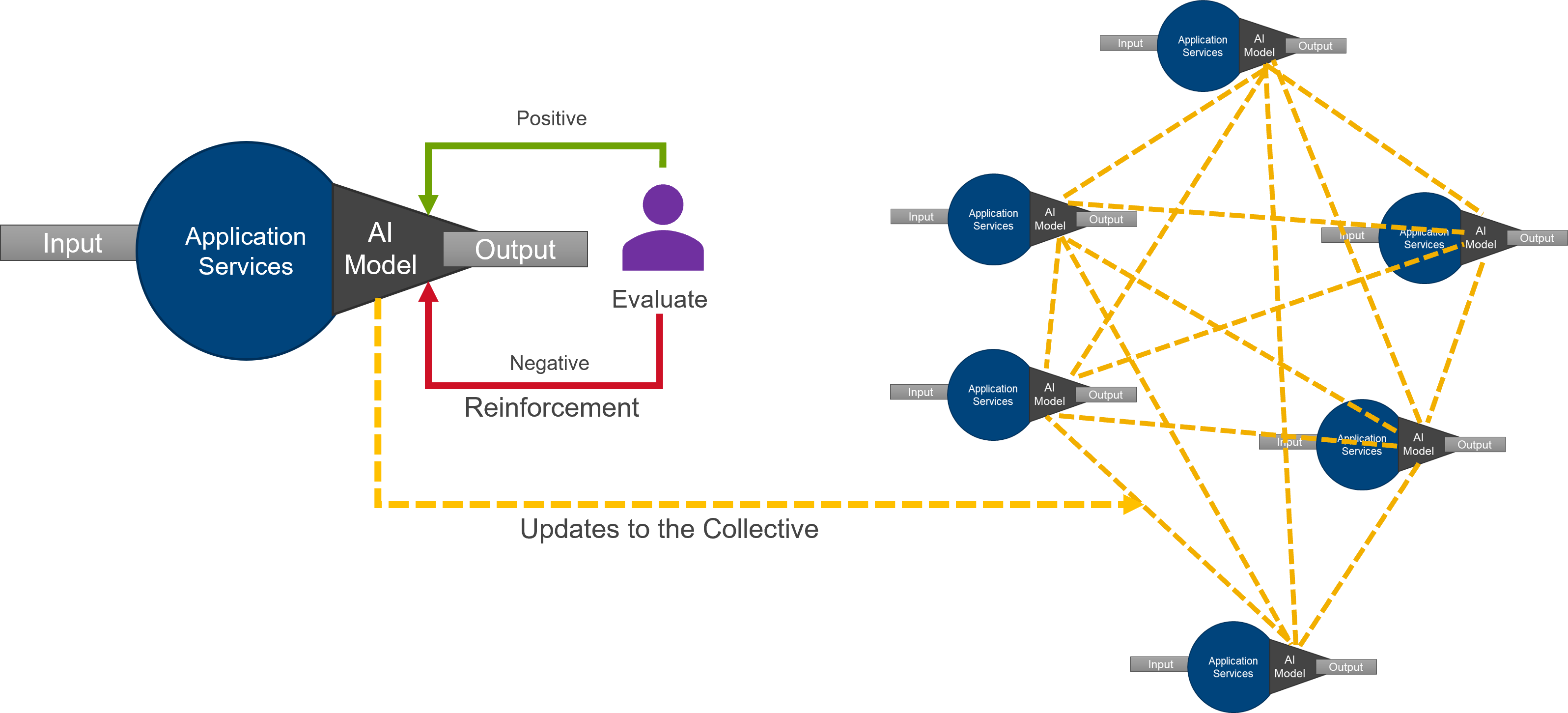
Managing AI models in these types of environments is non-trivial and requires forethought and a robust system approach that includes DevSecOps. This is exacerbated by the working environment of edge deployments, where thousands of devices need to be updated with several dozen AI model updates in a continuous stream of updates. A systematic approach is required to manage the complexity of accepting, validating and deploying dynamic and static AI model updates across the vast ecosystem. The SABR architecture provides the foundational elements to effectively manage AI algorithms at the edge.
The Learning Corpus is the intelligent, distributed repository of AI models. The Learning Corpus manages the AI models and their updates and tracks which SAPRs are utilizing which AI model. As Sailors interact with systems like DCGS-N that utilize the AI models, the AI algorithms can learn from model updates. These model updates are managed and validated in the Learning Corpus, then distributed to the SAPRs in the ecosystem. This feedback loop is critical to controlling inconsistencies in AI models in the distributed ecosystem.
Applicability
Fault Tolerance
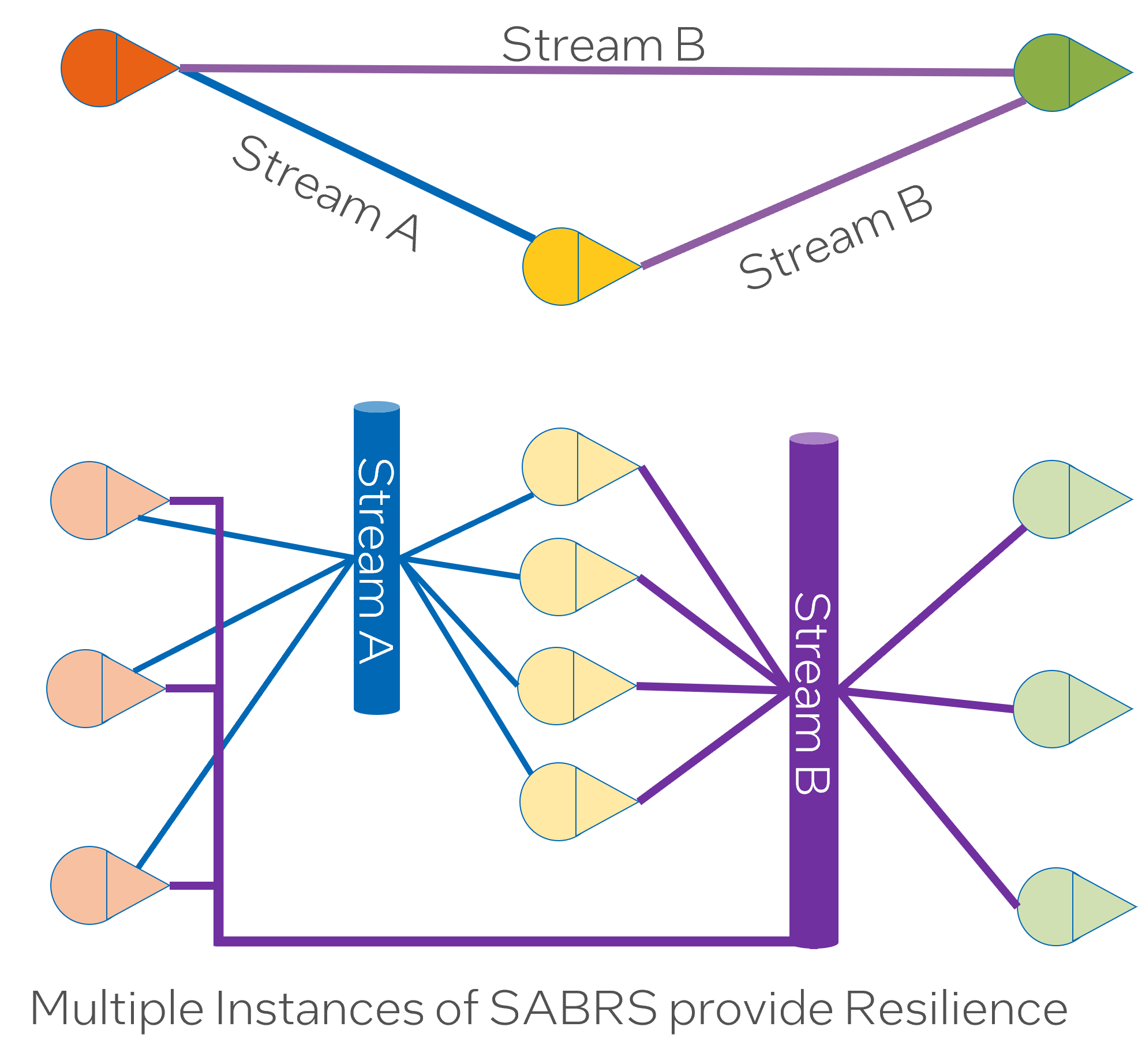
Fault Tolerance is an integral component of any resilient technology framework, especially within distributed systems such as SABR, which can be deployed universally across a Mesh network. The ability to self-recover and continue operations even during device or software anomalies enhances overall system stability and productivity.
Distributed SABRs possess an inherent capability to resume operations from the point of failure, making them inherently resilient. The ability to take over from a point of disruption minimizes standstill and ensures continuity within the system functions, thereby reducing downtime and ensuring the delivery of the services in a virtually non-stop manner.
Moreover, the strength of being able to operate on partial data is a critical attribute for SABR Mesh deployments. The system can process essential functions despite the potential adversities related to incomplete data transmission or system or component failure. This aspect boosts system robustness, ensuring it retains partial functionality while experiencing a system component or data flow obstruction.
In addition, this ability imparts operational elasticity - an essential characteristic for functioning in dynamic digital environments where system platforms constantly interchange - enter and exit the network. Adapting to varying system configurations and maintaining operations despite the frequent changes underscores the robust architecture of the framework.
In essence, Fault Tolerance forms the backbone of any complex digital system, more so in distributed setups such as SABR Mesh. By bolstering system stability, underpinning reliability, and ensuring that dynamic environmental changes or operation disruptions do not hinder system functionality, Fault Tolerance is indeed an indispensable quality that redefines the robustness and adaptability of distributed systems in an ever-evolving and sometimes volatile operational landscape.
Data Management and Processing Services
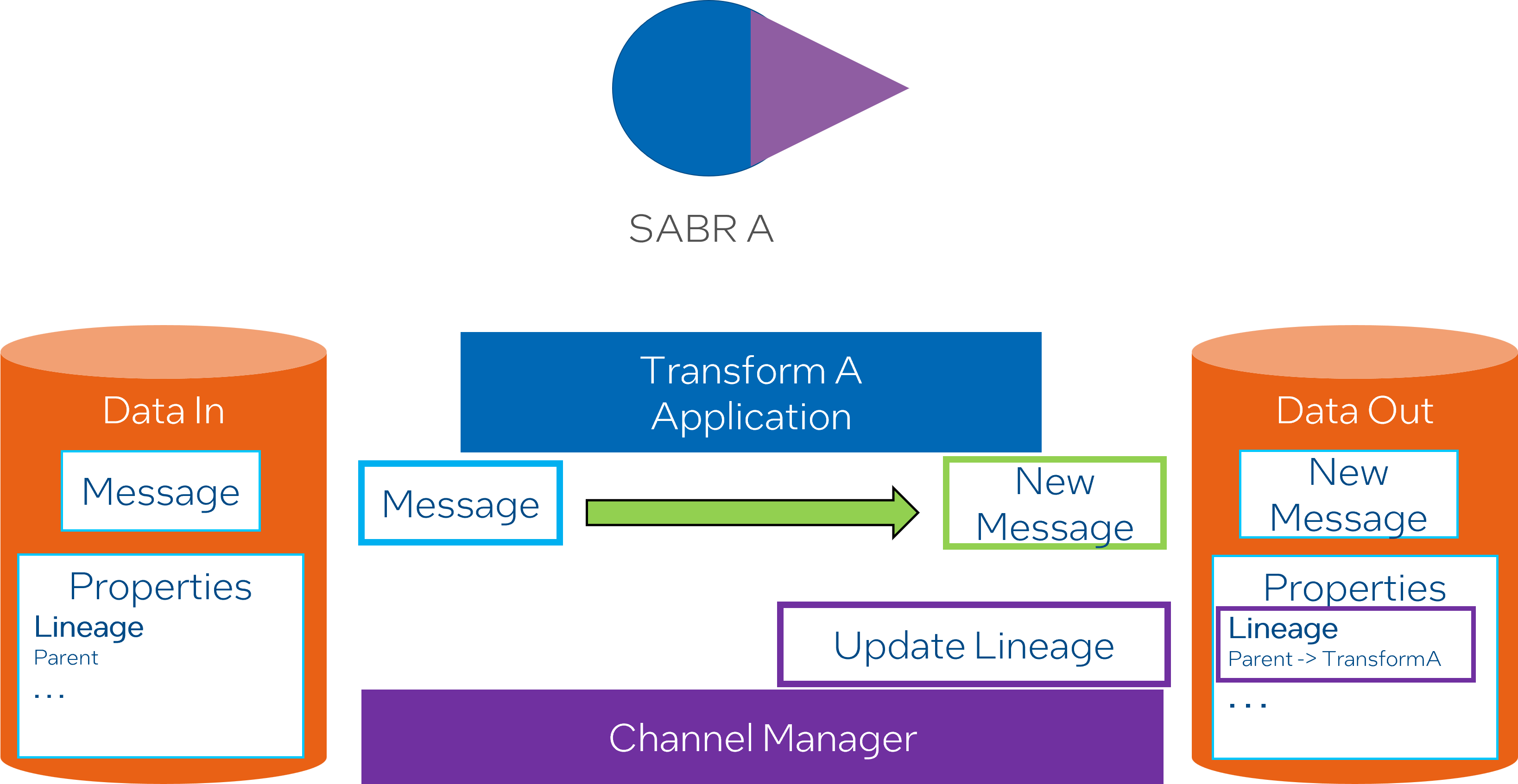
The realm of Data Management and Processing Services is integral to the proper functioning and maintenance of any system planned around data-intensive operations.
Understanding data lineage is a significant aspect of this realm. Data lineage refers to the life-cycle of data, including its origins, movements, characteristics, and quality throughout its journey in the system. Having a clear and detailed insight into data lineage bolsters the validity of derived data within the system.
Derived data refers to the information that has been computed or extracted from the base data. Enhancing the validity of derived data ensures that the information used for decision-making, analysis, or other purposes within the system is reliable and is based on sound data.
In the context of AI models, accuracy stands as a paramount aspect that determines their effectiveness and reliability. The accuracy of AI models is substantially increased when they are trained and tested using valid and reliable data.
Understanding data lineage plays a fundamental role in improving data management and processing services. It ensures that derived data and AI models within the system are more accurate, thereby leading to better decisions, insightful analysis, and more effective AI models.
Data Prioritization
Data Prioritization becomes a critical task in data management as all data is not created equal - some hold more relevance or significance than others. Hence, it is essential to prioritize and classify data according to its value or strategic importance to the system or the user.
The concept of ‘pushing data management to the edge’ refers to the decentralization of data management efforts. Instead of central, monolithic servers, data is processed, stored, and managed closer to its source, i.e., at the edges of the network. This approach is particularly beneficial in controlling data sprawl and preventing unmanageable expansion. Data sprawl refers to the large, uncontrolled, and often complex distribution of data across various locations and formats.
Applying data prioritization policies across the Mesh, SABRs, Platforms, and SABR instances ensures consistent and efficient data management. Through this process, data across disparate elements in the system is organized and processed according to its priority and importance.
Data Prioritization mitigates the risks associated with data sprawl and unmanageable data expansion. By providing a systematic way to push management to the edge and apply consistent policies across the system, it ensures that key data is identified and prioritized, enhancing the overall system’s efficiency and effectiveness.
Data Synchronization Between Clouds
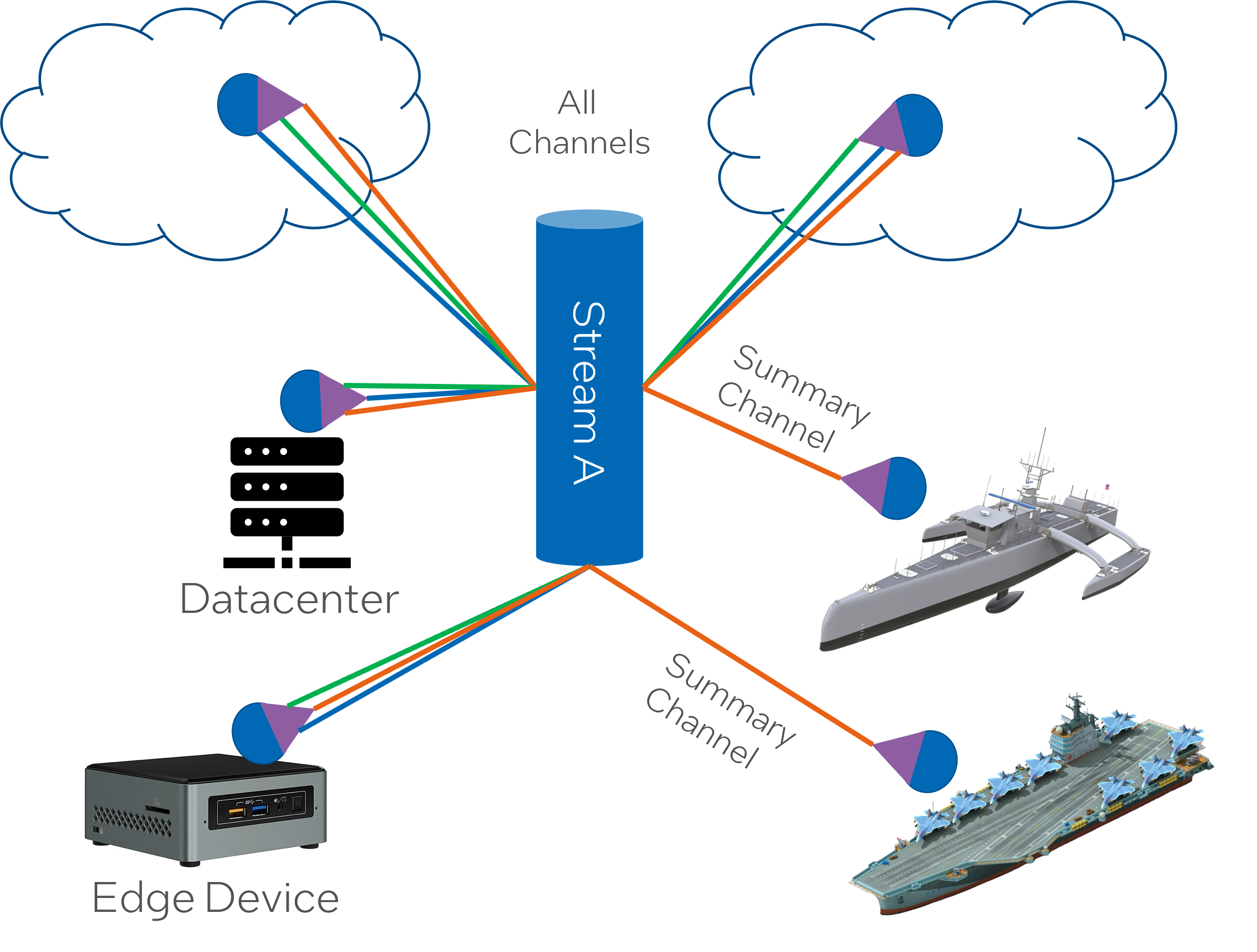
Data synchronization between clouds denotes the process of ensuring that data across different cloud platforms is in a consistent state, even as the data continues to be updated and changed across different cloud environments.
Differential channels allow for sophisticated control over how and where data is moved, based upon the current conditions of the Dynamic Data Integration Layer (DDIL) environment. The DDIL is the layer where the integration of data across different computing platforms takes place.
A policy-based mechanism helps in activating these channels based on present environmental conditions. Such policy-driven approaches let the system adapt to changes in the environment dynamically and ensure data movement operates optimally even under changing conditions.
Prioritizing data across these channels can provide a mechanism to decrease the impact of Network storms upon re-connection. Network storms typically refer to a surge in network traffic, which can cause delays or disruptions. By prioritizing data, the system can manage the amount of data being transferred upon re-connection, thus minimizing the potential effect of a network storm.
Handling data synchronization between clouds needs a robust strategy that can dynamically adapt to environmental conditions and manage data movement without causing disruptions in network connectivity. This strategy relies on using differential channels, policy-driven mechanisms, and prioritizing data to minimize network storms at re-connection times.
Data Priorization within Channels
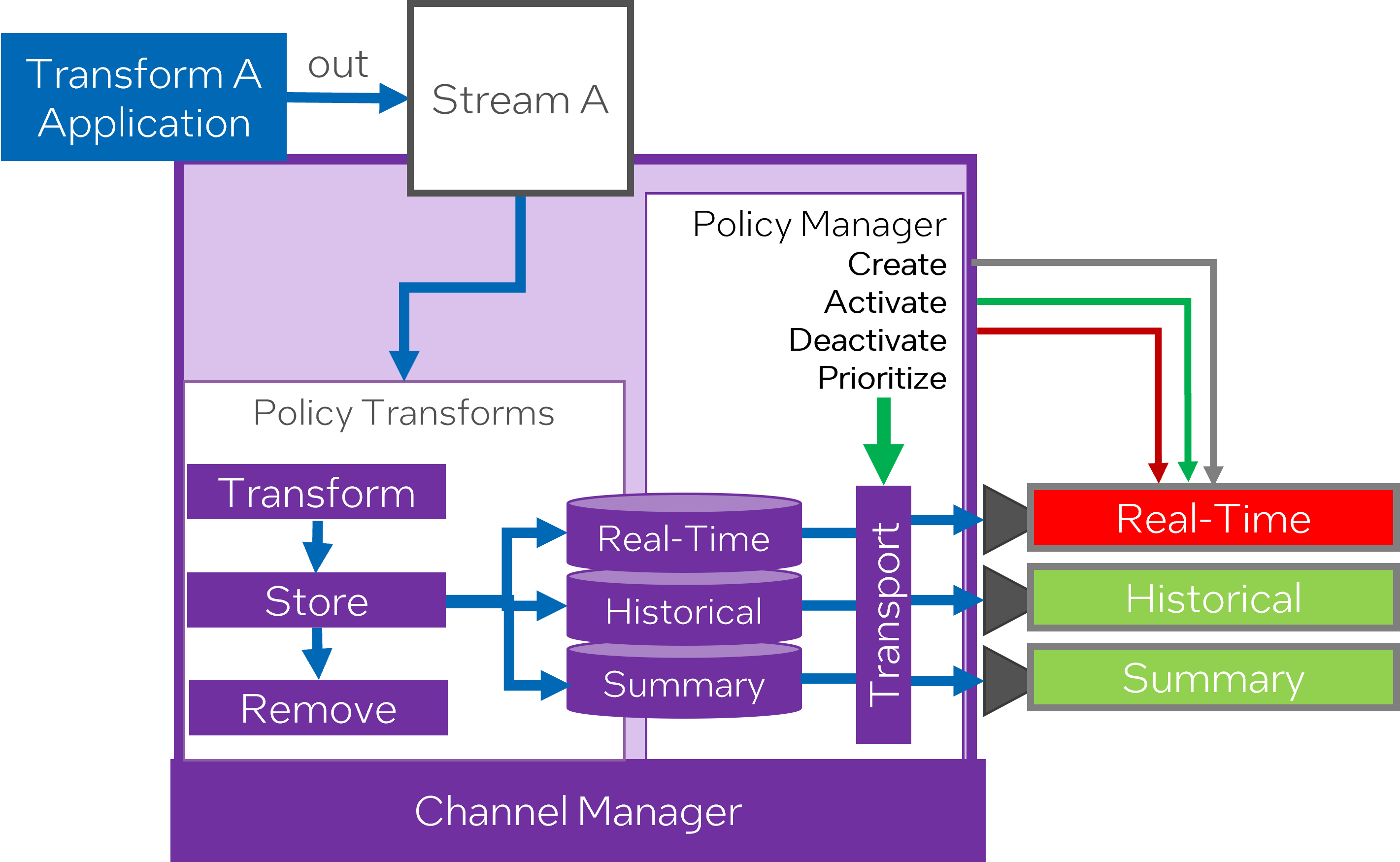
Data prioritization within channels signifies the process of ordering and grading the importance of data as it moves through various communication avenues or channels, based on pre-defined policies.
Channel policies are guidelines or procedures that determine how data is handled, processed, and prioritized within each channel. These policies are crucial for maintaining orderly data flow and prevent data congestion that can affect the efficiency of the system.
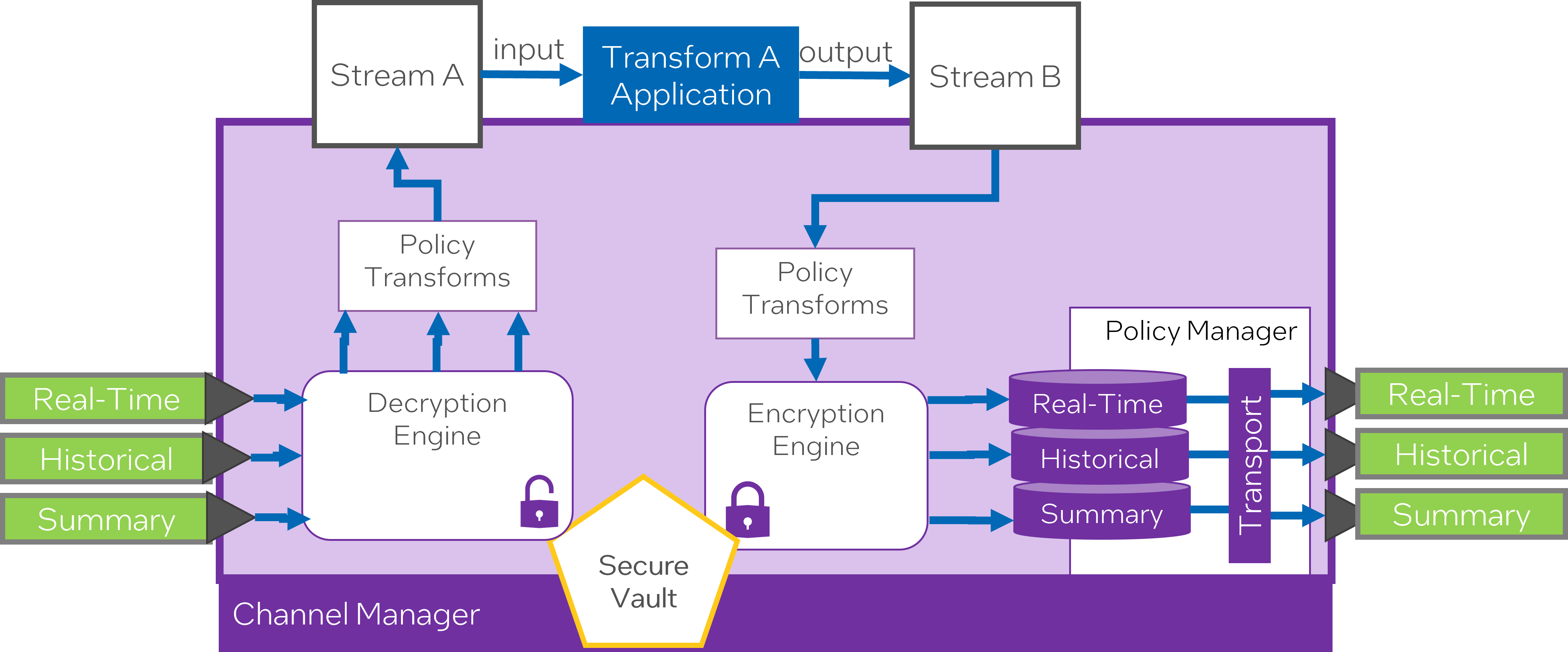
The Channel Manager plays a significant role in controlling the data flow across various channels for each data stream. It ensures that data is well-conducted and monitored according to the set policies, to assure optimal distribution and processing.
Adopting a policy-driven approach towards prioritizing data based on channels and streams provides an effective mechanism to manage massive amounts of data efficiently. It keeps the data flow structured and the channels well-distributed, enhancing the overall operational efficiency and accuracy of data transmission and processing.
Data prioritization within channels, managed by the Channel Manager and directed by channel policies, is a vital component of effectual data management and processing. It ensures system effectiveness by organizing transmission and optimizing the data flow across multiple channels and streams so that it meets projected outcomes.
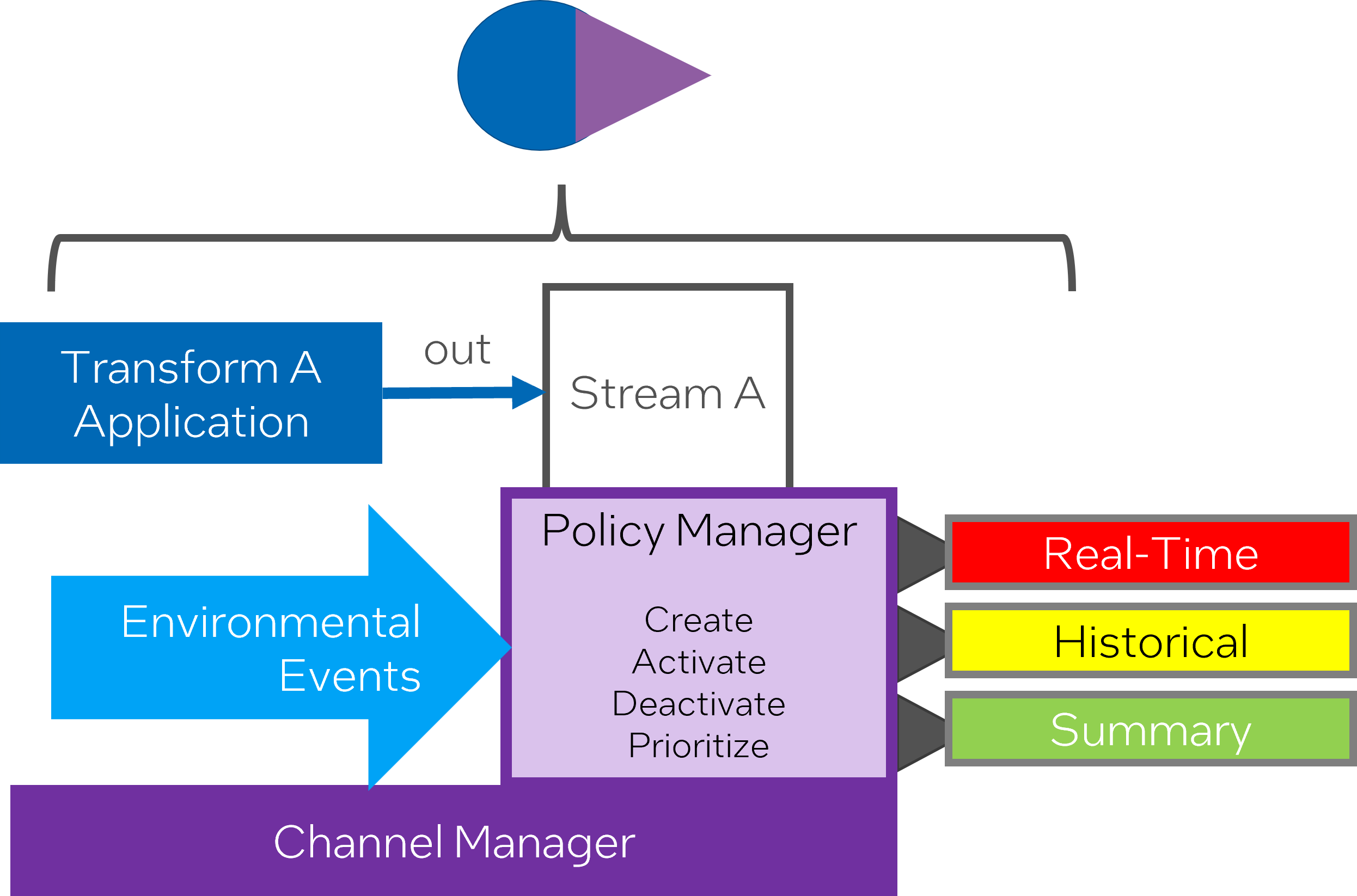
Policy Driven Channel Management
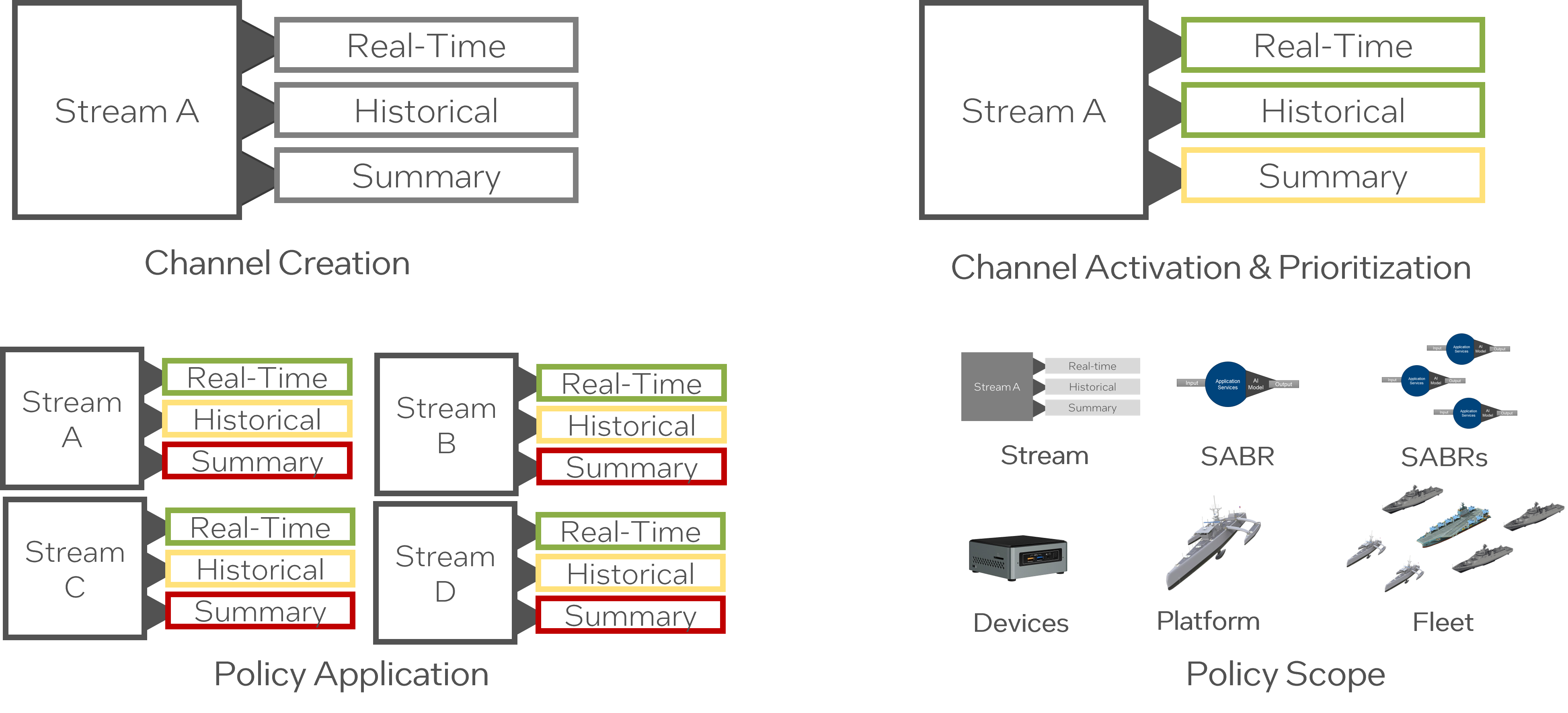
Policy-driven channel management is an approach where strategic policies guide the creation, activation, and data prioritization mechanisms in a system’s channels.
There are three kinds of SABR (Semi-Autonomous Bi-Directional Replication) policies governing this mechanism. These include:
-
Channel Creation Policy: This shapes how channels are set up within the system.
-
Channel Activation Policy: This policy dictates when and how channels will be activated for data transmission.
-
Data Prioritization Policy: This policy sets the criteria for determining the order in which data should be processed and transferred through the channels.
An essential aspect of these policies is their versatile applicability. They can be applied to individual SABRs, groups of SABRs, platforms, and even scale up to full deployment levels. This means that regardless of the scope—whether at an individual device level or a larger networked system—the channel management policies help ensure consistent and efficient data management.
The concept of policy-driven channel management provides a framework for effective and adaptable data management in systems like SABR. By defining strategic policies for channel creation, activation, and data prioritization, it’s possible to streamline data flow and significantly improve overall system efficiency.
Secure cross domain Data
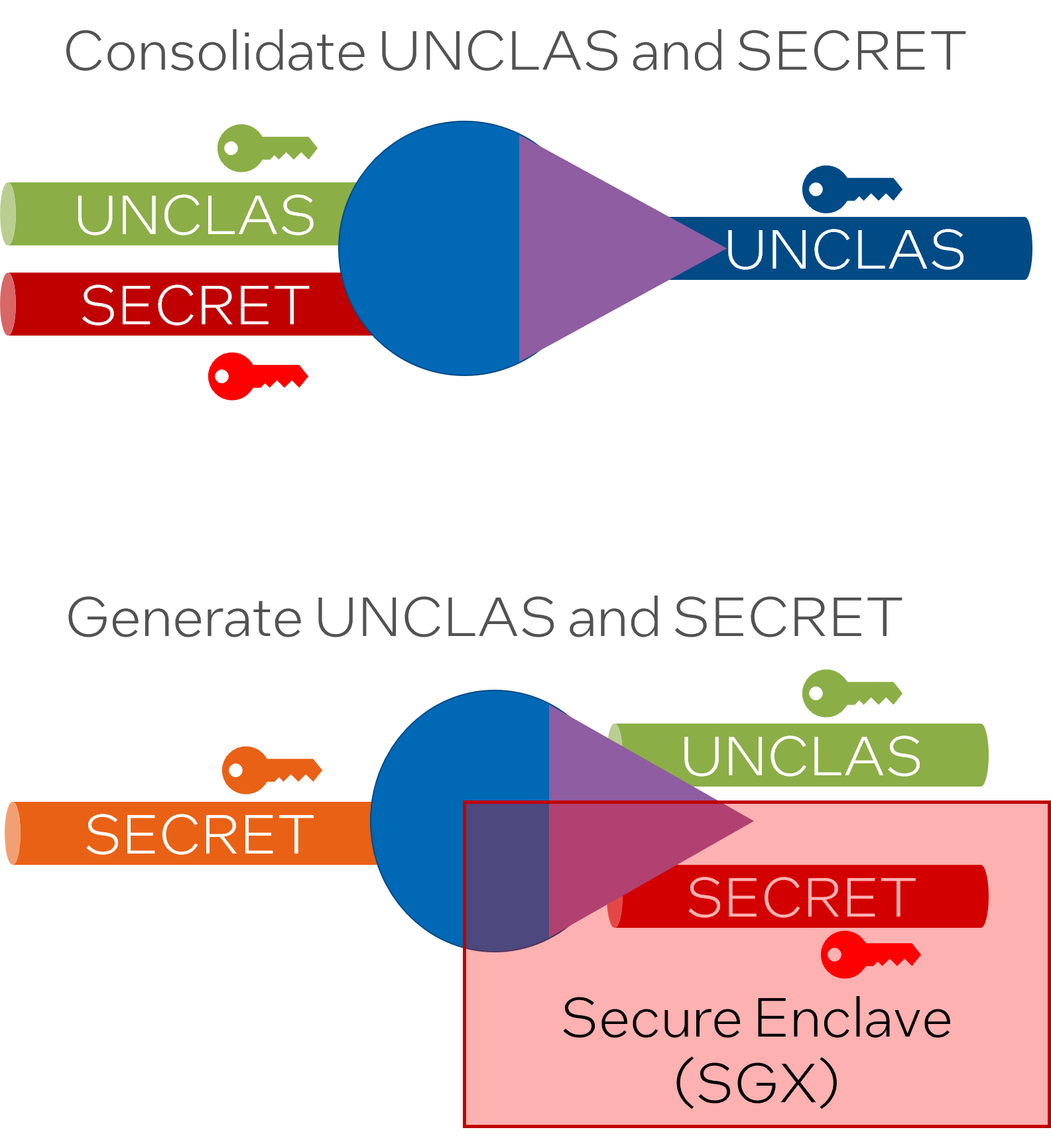
Secure cross-domain data refers to the methods and protocols used to ensure the safety and privacy of data as it is transferred and accessed across different security domains. Implementing effective security measures becomes vital in the contemporary data-oriented world, where data breaches and vulnerabilities can lead to significant losses.
Each data stream within a system like Semi-Autonomous Bi-Directional Replicator (SABR) is distinctly isolated. It features unique attestation and encryption keys, offering an extra layer of security. This means that even if multiple data streams are being used by the same SABR, each maintains its unique security attributes.
Attestation keys help confirm the data’s authenticity, ensuring that the data has not been tampered with during its transmission. Likewise, encryption keys help secure the data by converting it into a form readable only by authorized entities possessing the corresponding decryption keys.
Secure enclaves, like Intel’s Software Guard Extensions (SGX), are crucial when deploying cross-domain SABR solutions. These enclaves provide a protected area of a processor where code and data can be safe from disclosure or modification. This additional security layer is especially important for higher-security data streams and transformations, where data integrity and privacy is paramount.
Securing cross-domain data involves several components, including unique attestation and encryption keys for each data stream and the use of secure enclaves for additional protection. With such mechanisms in place, it’s possible to enhance data security, integrity, and privacy in a cross-domain environment.
Data-centric Security
Data-centric security involves implementing strategies and measures that focus primarily on safeguarding the data itself, rather than the networks, servers, or devices that store the data.
In the context of edge computing, many edge devices are often not physically secure from potential unauthorized users ( referred to as “prying eyes”). These devices are usually spread across various locations and may lack the robust security infrastructure available in centralized data centers, making them vulnerable to security threats.
To counteract this, data-centric security protects the data during its entire lifecycle - at rest, in transit, and while in use. Protecting data in use refers to implementing security controls to safeguard data while it’s being processed or manipulated, which gives an extra level of security to the data and its processing algorithms.
For instance, it may involve using techniques like encryption, tokenization, or anonymization to obfuscate data, rendering it unreadable or meaningless to unauthorized users, should they gain access.
Utilizing this approach, even if an unauthorized user gains access to the device or network, the data remains secure. This ensures that even in the face of possible breaches or threats, the integrity and confidentiality of the data are maintained, which is especially crucial when handling sensitive information.
Data-centric security plays a pivotal role in today’s data-driven world, providing robust protection mechanisms that keep data secure regardless of where it resides or how it’s being used.
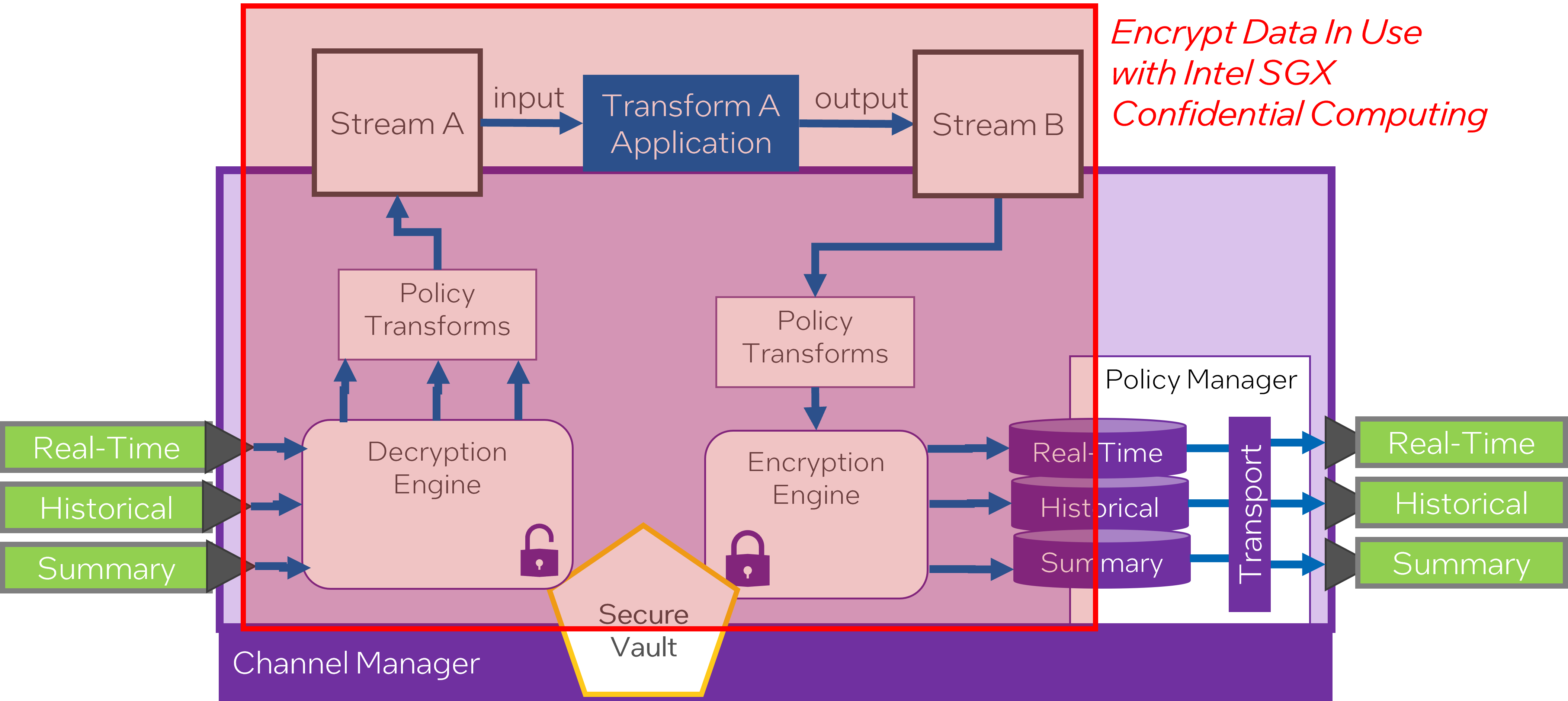
Sometimes, it is necessary to protect data even during its execution or processing, not just when it is at rest (stored) or in transit. In these instances, the use of Secure Enclaves is recommended.
A Secure Enclave refers to a secure area within a processor. This protected portion of the processor safeguards code and data from disclosure or modification. It forms an isolated execution environment, literally an ‘enclave’, within the software, adding an extra layer of security.
By operating in its own isolated environment, a Secure Enclave ensures that the data being processed is safe from outside interference, even from high privilege processes in the system. This is valuable in cases where sensitive data or algorithms might be subject to attacks aimed at reading or altering the data during its execution.
One popular implementation of Secure Enclaves is Intel’s Software Guard Extensions (SGX). Intel SGX allows developers to partition their code and data into private regions of memory, called enclaves, which are designed to be more secure.
Overall, the use of Secure Enclaves significantly increases the security of data while it is in use, offering protection during execution and ensuring the integrity and confidentiality of the data being processed.
ABAC Integration
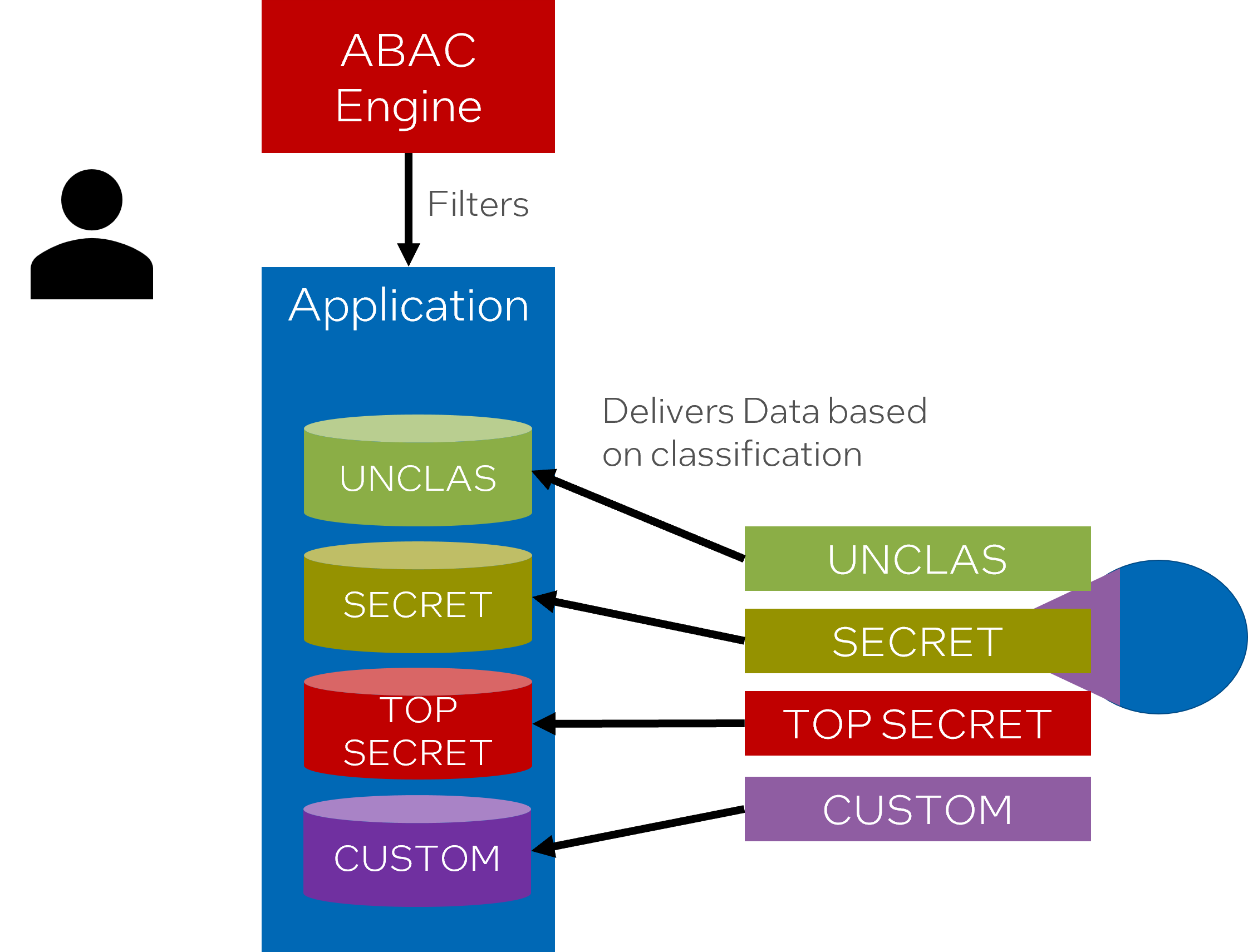
Attribute-Based Access Control, or ABAC, is a powerful and flexible access control methodology that uses attributes associated with users, resources, and environmental factors to define access control policies.
ABAC, when integrated into a system like Semi-Autonomous Bi-Directional Replicator (SABR), provides access control to application data. This access is tied to data streams and channels, effectively managing how data is accessed in complex environments.
By leveraging ABAC, access to data becomes primarily a function of attributes tied to the user. Users must first authenticate themselves to the applications they use to access the data streams and channels. This ensures that only authenticated users can access the data.
In addition, this access control model can be associated with the type of channel involved. This means access is not merely an all-or-nothing deal, but instead can be fine-tuned based on specific factors. Each user can be granted or denied access to the respective channels based on their attributes as determined by ABAC policies.
Attestation, in this context, refers to the process of verifying a user’s credentials or attributes. When a user is attested to a channel, their access is granted based on these verified credentials.
Access control, under the ABAC model, can be applied and managed at a fine-grained level, down to individual data streams or channels. This means that access permissions can be different for each stream or channel, adding nuanced control and increased security.
Therefore, by integrating ABAC, the system gains a flexible and sophisticated access control mechanism that can adjust to different users and different requirements, offering significant advantages in terms of data security and management.
ICAM
ICAM (Identity, Credential, and Access Management) is a framework for managing digital identities, authenticating users and devices, and controlling access to resources. It is a crucial aspect of securing resources and managing access in distributed systems.
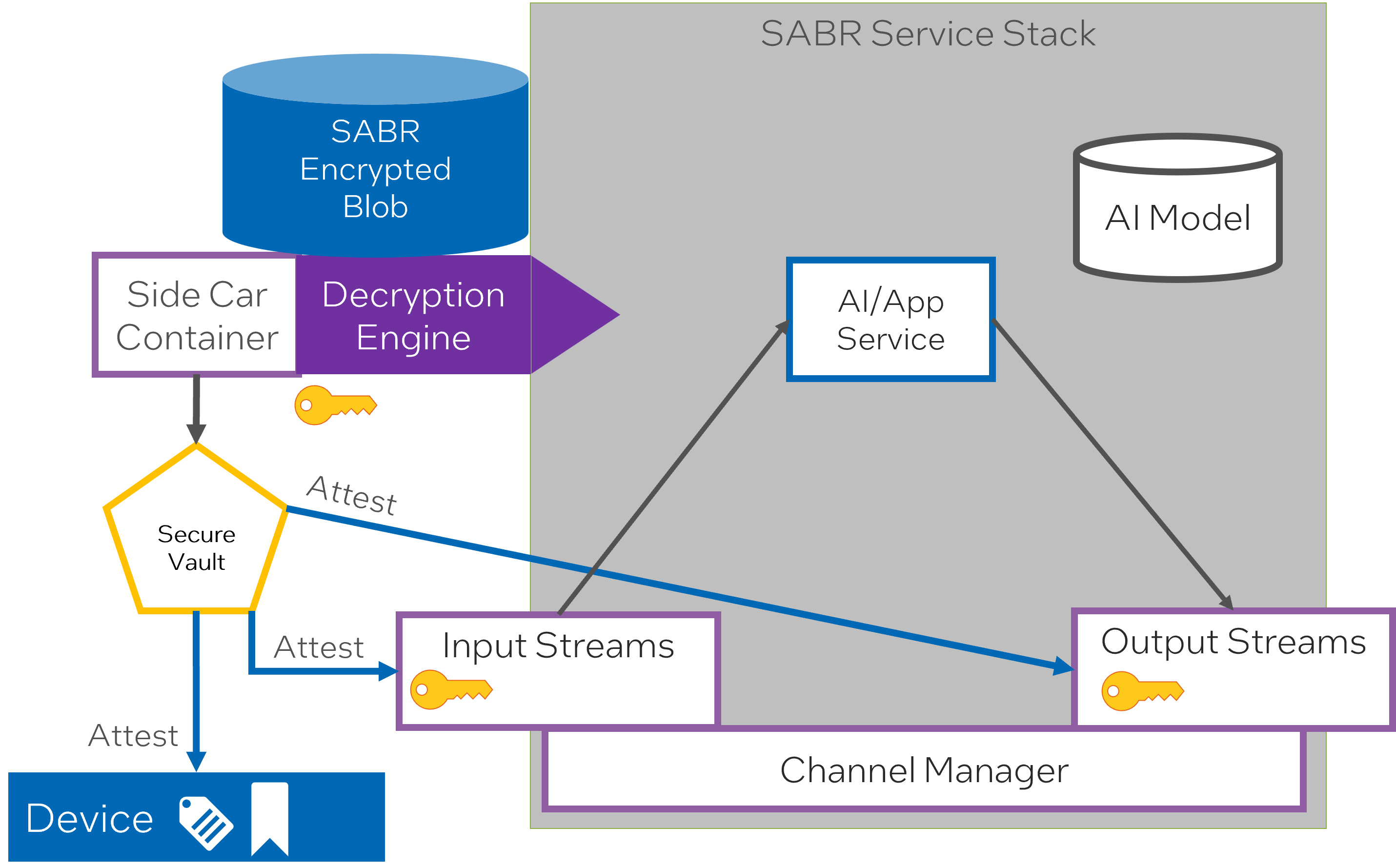
The mentioned text outlines a process involving SABR (Semi-Autonomous Bi Directional Replicator) and ICAM. Following are the steps in the procedure:
- SABR attests against a Device: Attestation in this context refers to the process of validating a device’s identity and integrity. SABR establishes trust with the device through an attestation process, ensuring the device is what it claims to be.
- Decryption Key Generated: A decryption key is generated using a seed and keys from a secure vault. The secure vault is a protective environment for storing sensitive data, such as keys and credentials. The seed is a unique value or set of values used as an input for the key generation process.
- Decrypt the SABR Encrypted Blob: The generated decryption key is used to decrypt a ‘blob’ of data encrypted by SABR. A ‘blob’ or Binary Large OBject refers to a collection of binary data stored as a single entity. This could contain various types of data, including files, multimedia objects, or even software.
- Deploy SABR Service Stack: The decrypted data blob likely contains information or components necessary for deploying or configuring the SABR service stack - a collection of services that work together to enable SABR’s functionality.
- Attest Each Input and Output data streams to the SABR: Each of the input and output data streams going into and coming from the SABR service are attested. This means their identities and integrities are validated, ensuring trustworthy communication and data transfer.
- Generate Encryption and Decryption keys from seed and hashes in the secure vault: Further encryption and decryption keys are generated, again using seeds and hashes stored securely in the vault. These keys are essential for maintaining secure communication and data transfer in the system, allowing data to be encrypted and decrypted as needed for secure processing and transfer.
With these steps, ICAM ensures the secure workings of SABR, validating identities, managing access, and maintaining the confidentiality, integrity, and availability of the data it handles.
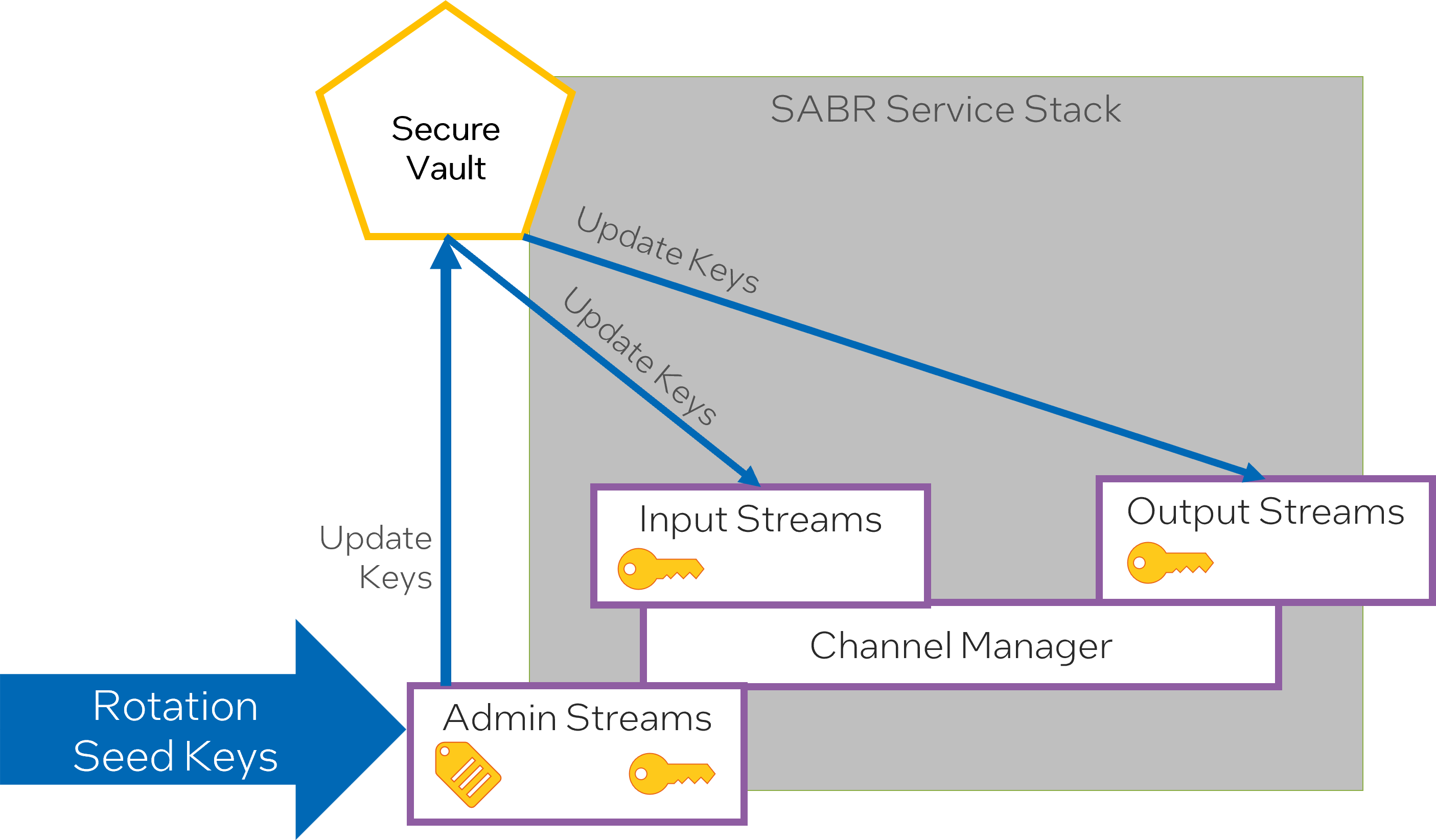
- Admin Stream allows Federated Key Manager to send new key/seeds to the SABRs.
The Admin Stream appears to be a secure communication channel specifically used for management tasks. Here it’s being used to distribute new cryptographic keys or seeds, generated by the Federated Key Manager, to the SABR (Semi-Autonomous Bi-Directional Replicator) devices. A Federated Key Manager suggests a system where keys are managed and used across multiple trusted entities, or ‘federations’.
- New key/seeds are distributed to the secure vault to be used by the encryption and decryption engines in the Channel Manager
The new keys or seeds, once sent to the SABRs via the Admin Stream, are stored in a secure vault. The term ‘secure vault’ typically refers to a secure storage system where sensitive data such as cryptographic keys are kept. These keys will be used by the encryption and decryption engines running in the Channel Manager. It indicates that the Channel Manager has components or systems responsible for encrypting and decrypting data, most likely to provide secure communication channels.
- Old keys are kept to handle encrypted data with older keys.
This means that even when new keys or seeds are distributed and start being used, old ones are still kept for some time. This can be necessary to decrypt data that was encrypted with those old keys.
- Temporal data shifts are possible because of DDIL environments and asynchronous data delivery.
Temporal data shifts refer to changes in data over time. A DDIL (Distributed Dynamic Information Logistics) environment, which involves the distribution and management of data in a dynamic and distributed manner, can lead to these shifts. It means your data’s state could change over time due to its nature (i.e., dynamic) and how it’s handled (asynchronously delivered), which is not simultaneously or in real-time. For instance, a piece of data might arrive later or get updated after it was initially received and processed.
Data Producation and Lineage
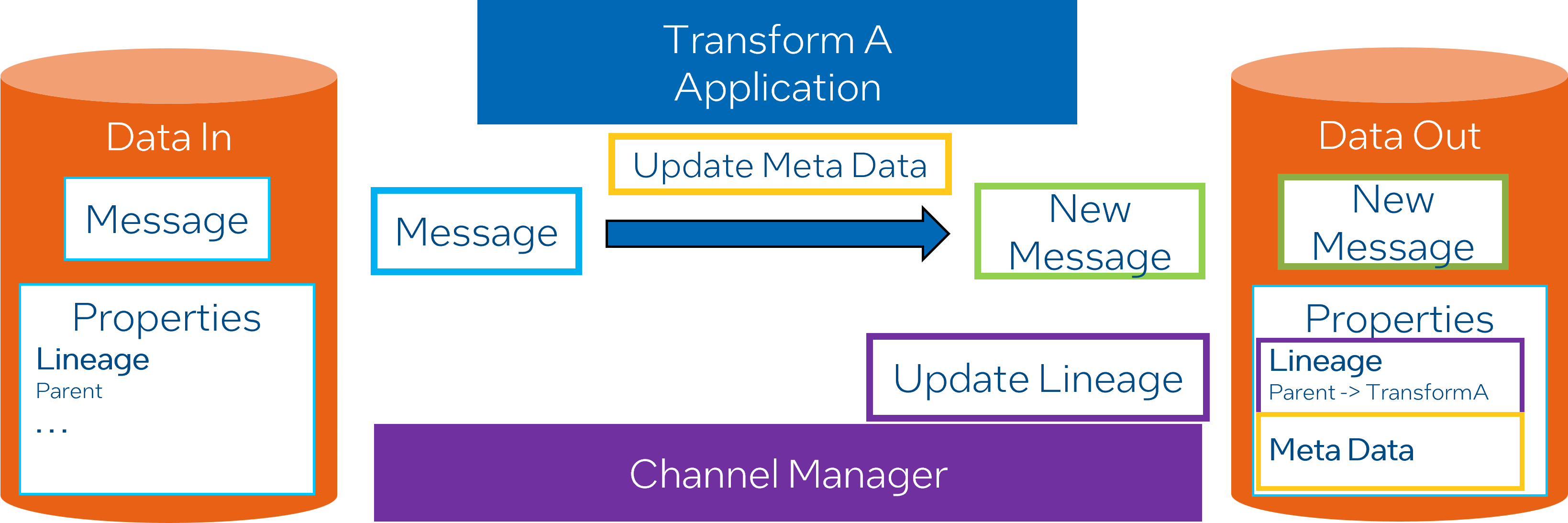
When data is processed through algorithms and channel policies, metadata is added to it”, refers to data undergoing specific processing procedures defined by algorithms and policies. As part of this processing, metadata is attached to enrich the data.
Data lineage is generated by default, which helps to track the data as it flows through the system”, refers to the lifecycle of data, its origins, movements, transformations and how it interacts within the system. This information is automatically captured and creates a trail for transparency and traceability of the data within the system.
Transformations update both the data and metadata for the output data”, means that as data goes through transformations using certain rules or algorithms, both the data and its associated metadata are updated to ensure that the metadata continues to accurately reflect the state of the data.
Data Programing Interface
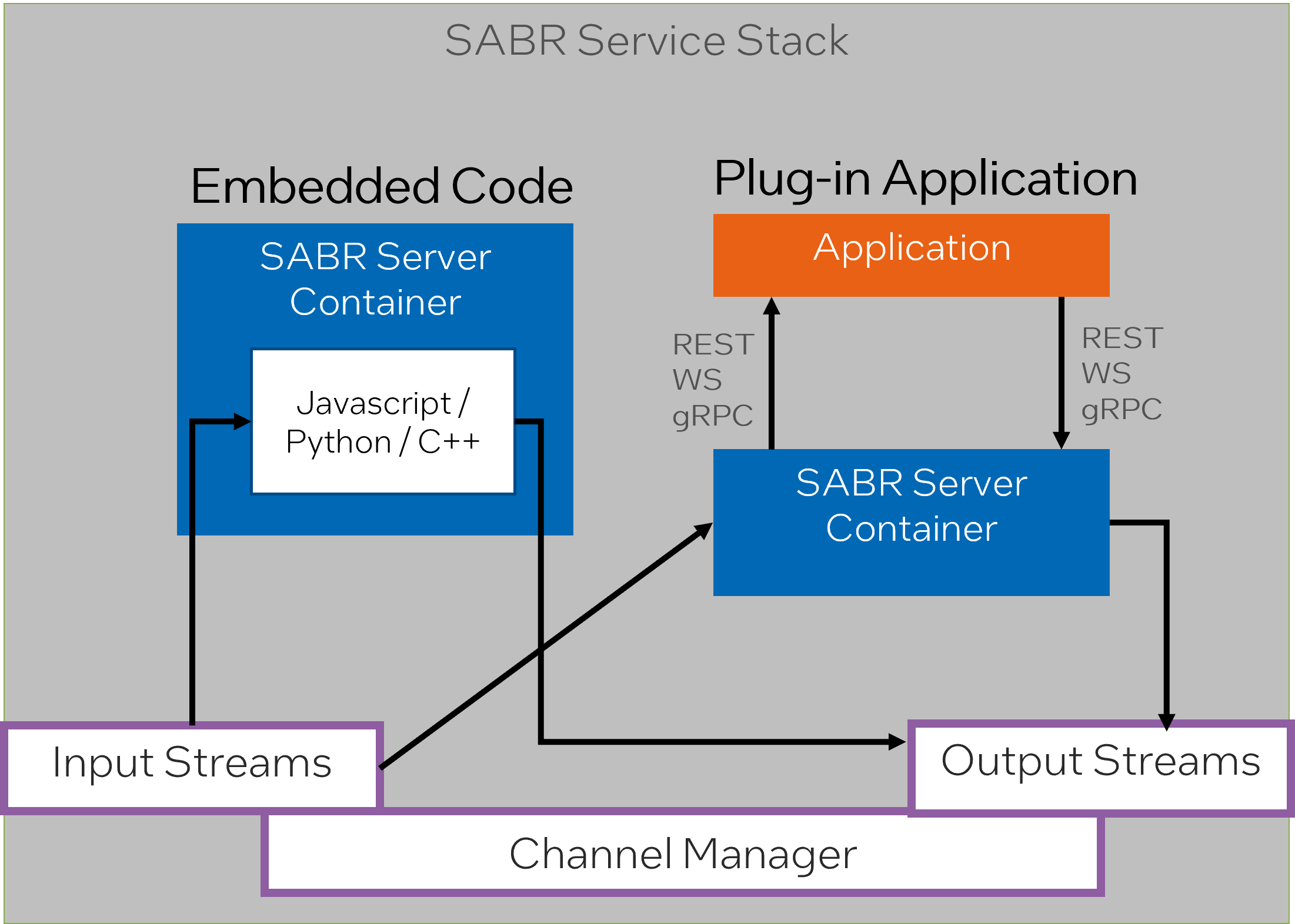
The SABR Development Interface supports multiple programming languages and data transport methods”, describes the flexibility and versatility of the SABR Development Interface. It is designed to accommodate numerous programming languages, which means developers can program using their language of preference. Furthermore, it is also able to handle different data transport methods, allowing for compatibility with various data protocols.
Embedded code reduces latency and memory usage by sending data directly to the algorithm running in the same container”, elaborates on one of the ways to optimize performance in this system. By embedding code and sending data directly to the algorithm in the same container, latency can be minimized and memory usage reduced. This is because the data does not need to travel through the network to reach the algorithm; it’s already in the same environment.
The Plug-in Application enables seamless integration with AI algorithms utilizing WebSocket, REST, or gRPC interface while running in separate containers”, explains how the Plug-in Application aids in easy integration with AI algorithms. These algorithms may be harnessing different types of interfaces such as WebSocket, REST, or gRPC. The wording suggests that while these AI algorithms might be running in separate containers, integration is still smooth and effortless with the help of the Plug-in Application.
Analytics Use Case
For the purpose of this example, AIS refers to the Automatic Identification System used in navigation for vessels. AIS data contains information such as the ship’s identity, type, position, course, speed, navigational status, and safety-related information. Analyzing AIS data is crucial for maritime safety, security, and effective vessel traffic management.
This use case highlights the processing and analysis of such AIS Ship data. It aims to identify particular scenarios that are typical in this analysis. These scenarios could involve detecting potential collisions, securing marine borders, or fishing activities monitoring, based on the specifics of the data and the analytical framework used.
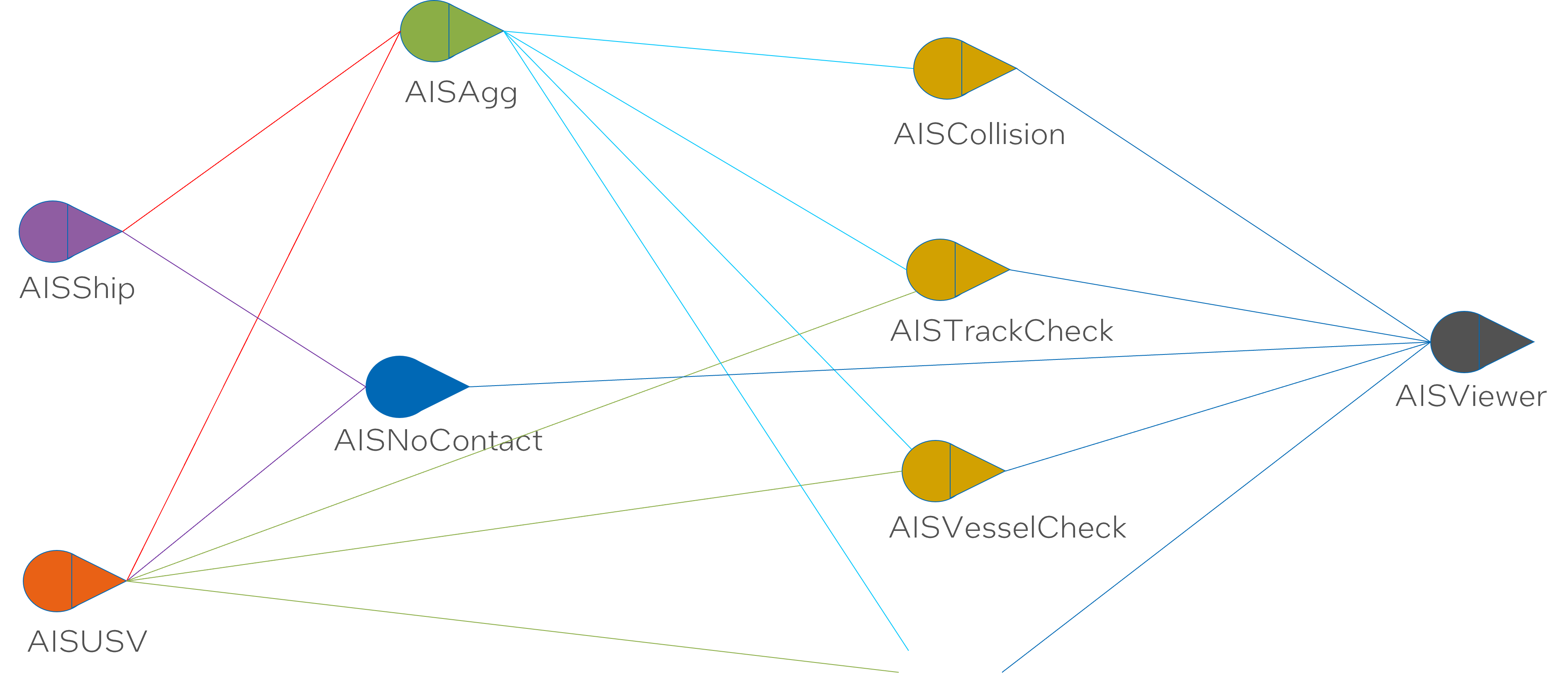
In computing and systems design, a logical architecture describes the structure and behavior of an application or system. It defines the components or building blocks of the system and the relationships between them. However, unlike the physical architecture, it does not concern itself with physical details like hardware or deployment locations.
Said section or diagram will ideally provide insights into the components, their association, communication flow, principles, rules, and constraints governing or guiding the system’s design and evolution.
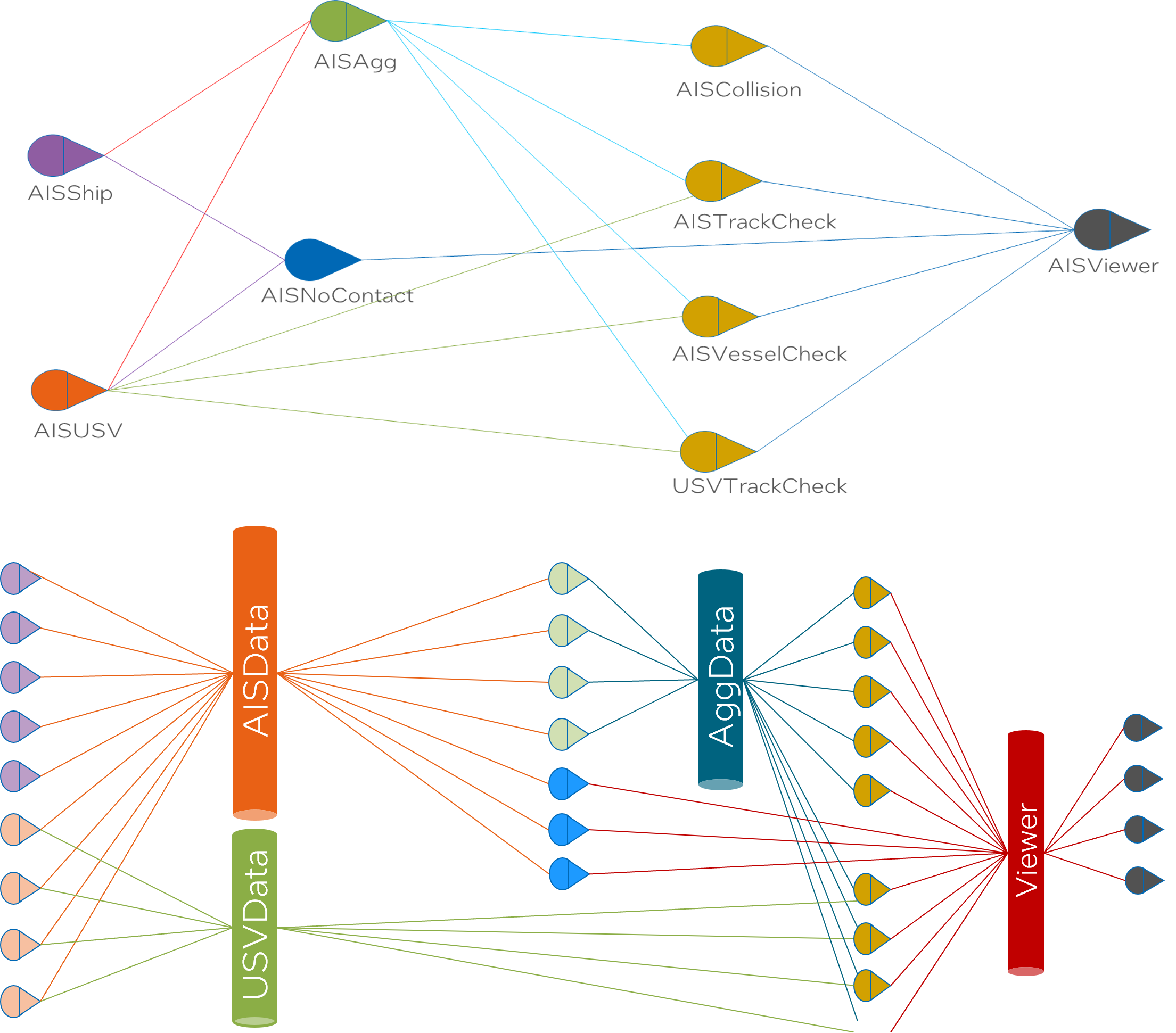
The SABR mesh enables deployment of multiple instances for edge and datacenter capabilities. This statement explains that the SABR mesh supports scalable deployment. It can have multiple instances running, both on edge devices (like IoT devices) and in data centers. This capability allows for flexible deployments, improving performance and reducing latency, especially in distributed architectures.
The redundancy of SABRs provides resilience. The system’s design with abundant SABRs (instances) promotes resilience. If one instance fails, the system can still continue to function using the remaining instances, hence improving fault tolerance and system availability.
Decoupling SABRs enables quick addition of new capabilities via new transformations. SABRs are decoupled, meaning they operate independently from one another. This structure facilitates the quick addition of new capabilities. When a new transformation (a way to manipulate data, probably in the context of machine learning or data processing here) is introduced, it can be independently added to or removed from a SABR without affecting other SABRs. This design makes the system flexible and responsive to changing needs or requirements.
Federated Governance
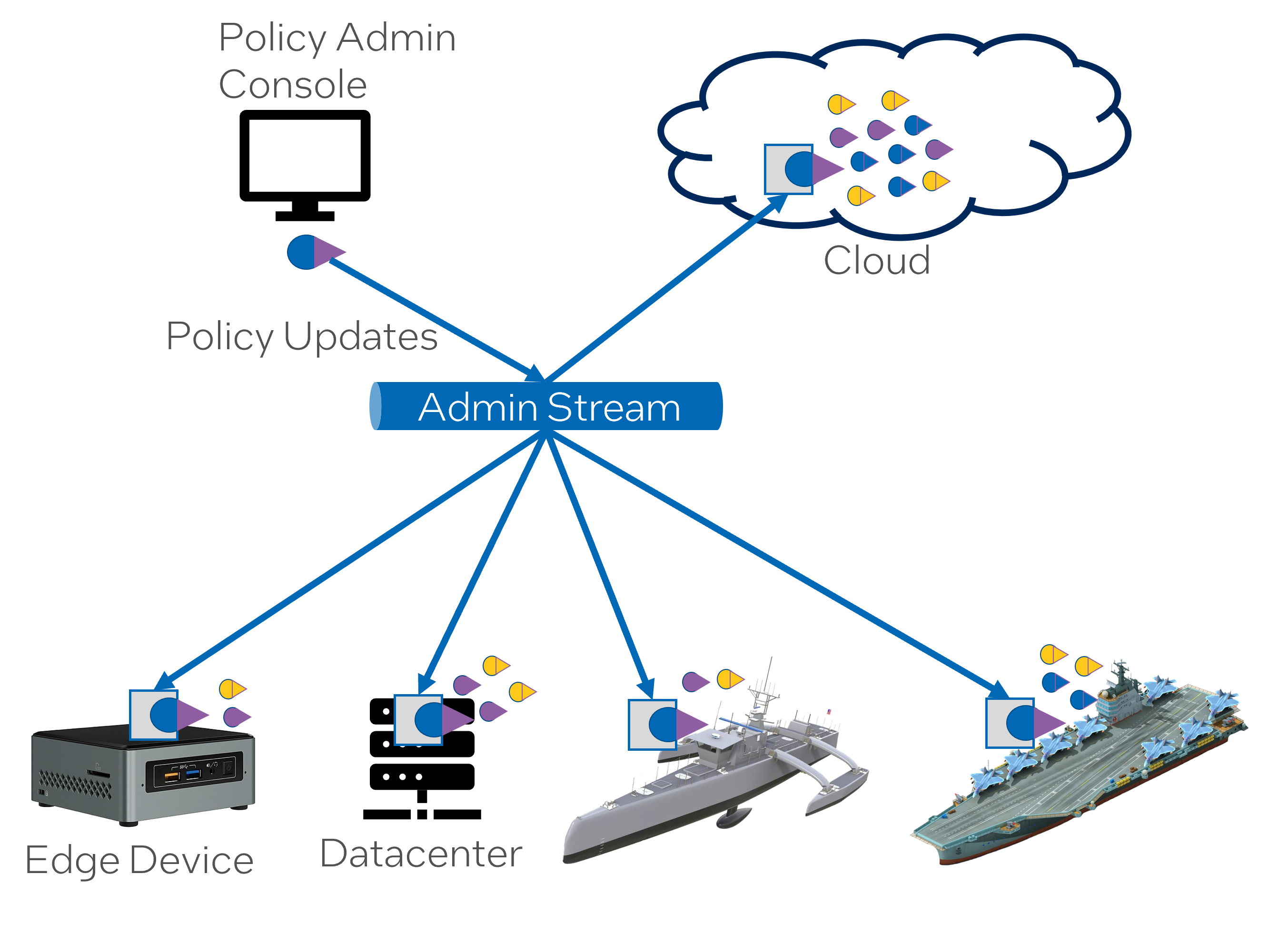
Federated Governance” is the overarching concept here. In a general context, federation in computing refers to a system that unites smaller systems while letting them operate independently. Governance refers to the way the rules, norms, and actions are structured, sustained, regulated, and held accountable. Together, Federated Governance typically means a structure that allows different participants to set and enforce governance rules while still interacting in a larger system.
“Policies are sent through the ‘Admin Stream’ and received by the ‘Seed’ SABRs on all devices.” This sentence suggests that in your system, governance takes the form of policies. These are sent through a specific “Admin Stream” and received by “Seed” SABRs, which likely serve as the initial point of contact or data source for devices in the SABR mesh.
“Policies can be applied to the complete mesh, SABRs, platforms, or any combination of SABR instances.” This statement implies that these policies have a broad scope. They can apply to the entire mesh, individual SABRs, particular platforms, or any combination of instances. This gives the operators of your SABR ecosystem tremendous flexibility in setting rules for data management, operability, information security, etc., at various levels.
“Policies are responsible for managing the creation, activation, and deactivation of channels.” The last sentence indicates that these policies control crucial aspects of your system’s operation - namely, the creation, activation, and deactivation of communication or data channels. These channels could be routes for data flow, interfaces between system components, or points of interaction with users/devices. By managing these elements effectively, the system can maintain data integrity, secure its operations, and manage system resources efficiently.
DevSecOps to Deployment
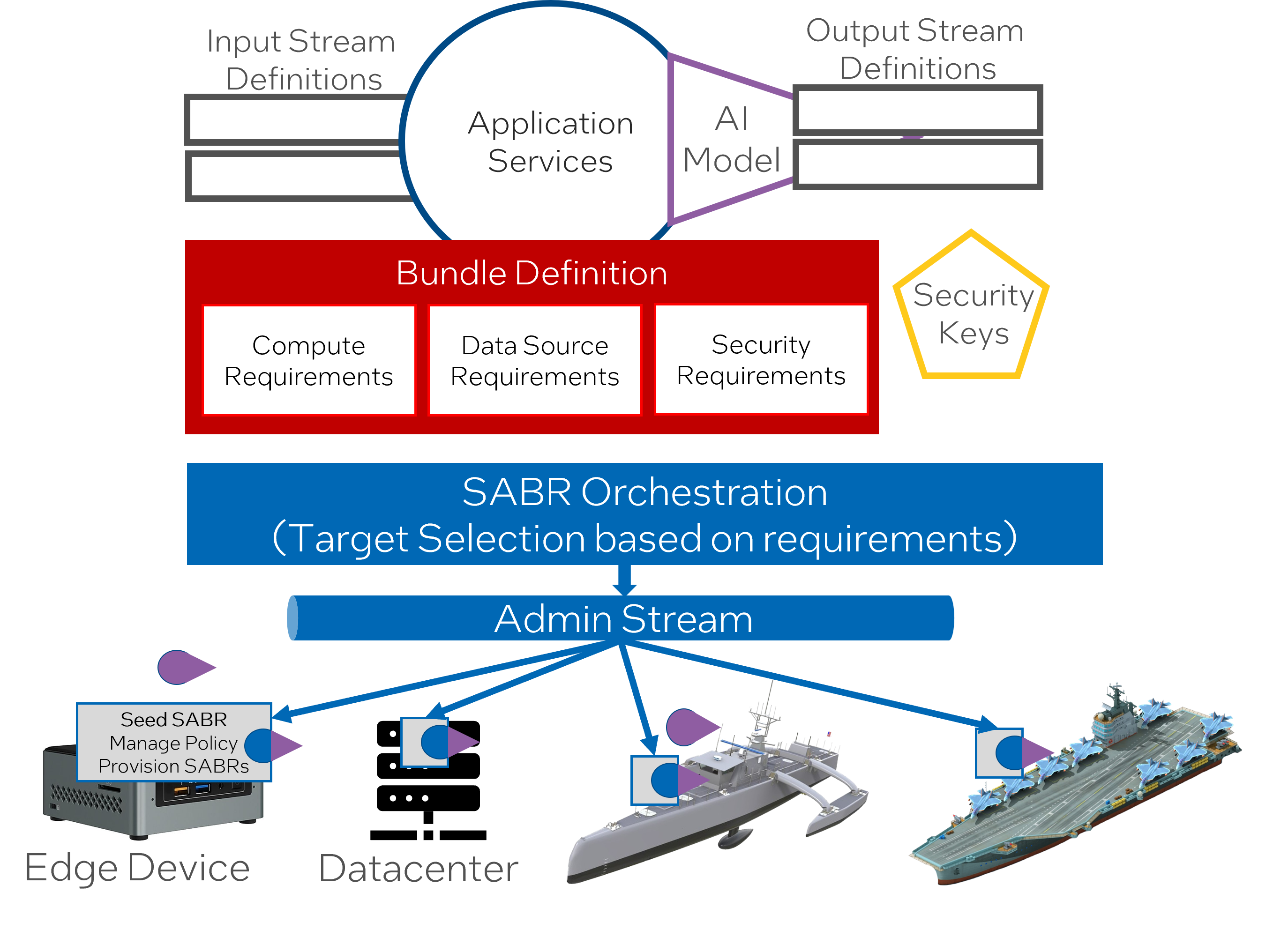
“DevSecOps to Deployment” refers to the incorporation of security practices into the DevOps approach. The DevOps approach aims at integrating development (Dev) and operations (Ops) processes to provide continuous integration and deployment. When security is integrated into this process it is referred to as DevSecOps. The goal of DevSecOps is to make everyone accountable for security and to implement security from the initial stages of development, rather than as a separate stage.
“The Seed SABR platform provisions SABRs, manages policies, and reports on the health of the device.”: The Seed SABR platform’s role is to provision new SABRs (probably meaning to prepare and configure resources for these instances), handle policy management, and monitor and report on the health of the devices that the SABRs run on. This combination of tasks suggests robust management and surveillant capabilities, facilitating efficient and secure operations across the SABR mesh.
“SABRs are targeted based on resource requirements, including device capabilities, data sources, and security needs.”: The allocation or targeting of SABRs is determined by various resource requirements. Factors such as the device’s capabilities, data source requirements, and specific security needs influence which SABRs are deployed where. This means that the deployment of SABRs is not homogeneous but is instead, fine-tuned according to each situation’s requirements.
“Control the cardinality of SABR instances through policies at different ecosystem levels.”: Cardinality in this context likely refers to the number of SABR instances in operation. The text suggests that one can regulate this cardinality via policies implemented at different levels of the system. This control method offers flexibility, as operators can adjust the number of active SABRs according to the current needs and circumstances of the ecosystem.
Continuous Authorization to Operate.
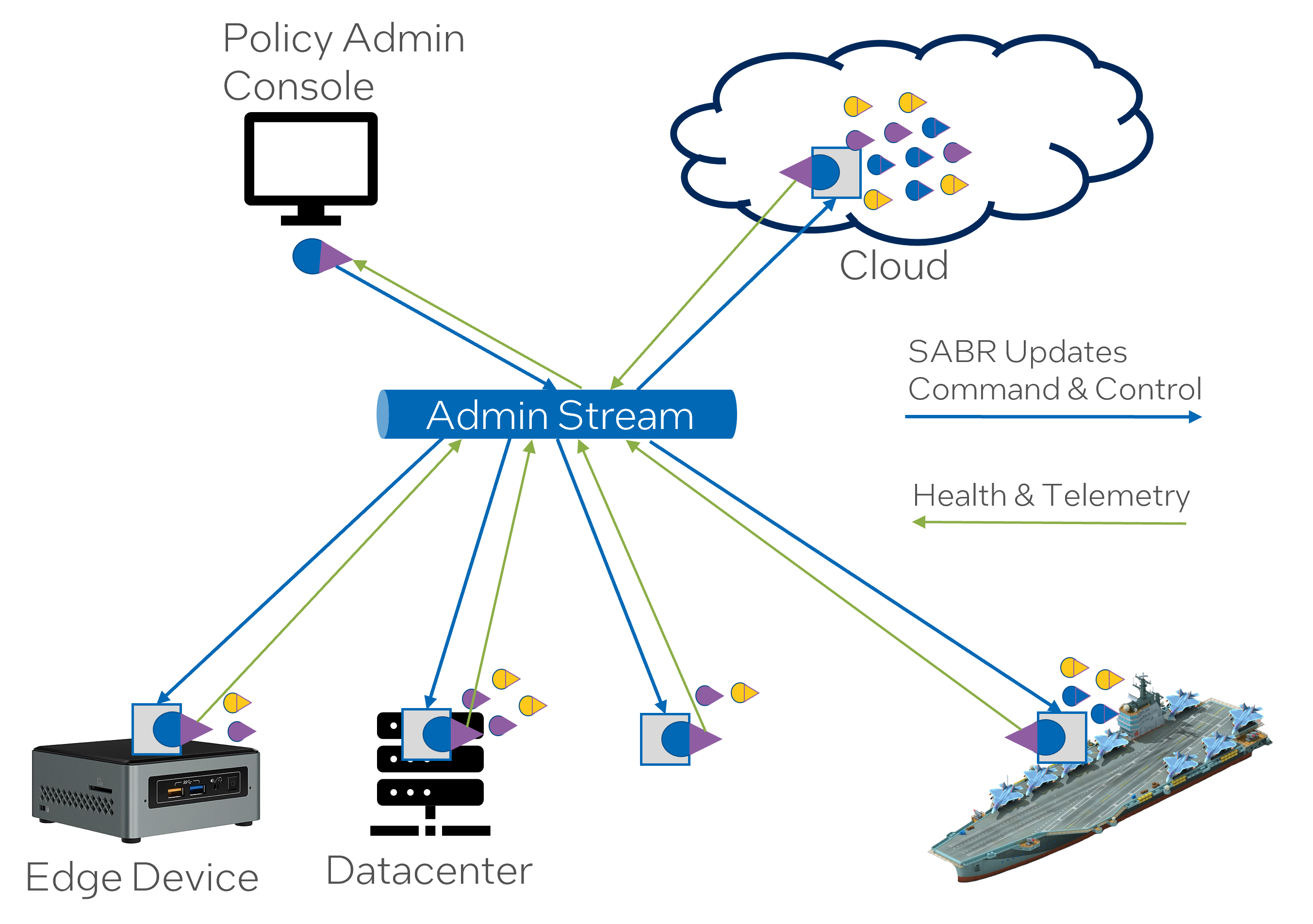
“SABRs are monitored through the Admin Stream through telemetry.” This statement indicates that SABR instances are undergoing continuous monitoring through telemetry data transmitted via an Admin Stream. Telemetry involves the process of recording and transmitting data from remote or inaccessible points to IT systems for monitoring.
“The DevSecOps process ensures that SABRS are encrypted before deployment.” Here, it’s indicated that SABRs are encrypted before their deployment as part of the DevSecOps process pathway. This step is crucial in enhancing security measures to protect data integrity and confidentiality.
“SABR Dashboard and “Admin Stream” give visibility into SABR and device health.” In this sentence, it’s revealed that the health status of SABR and devices can be monitored in real-time through the SABR Dashboard and Admin Stream. This enhances proactive actions to mitigate any potential threats or issues.
“Integration with a Risk Management Framework.” Lastly, the integration with a Risk Management Framework implies that risks are systematically identified, analyzed, evaluated, and treated. It provides a structured approach to managing uncertainty and making the best possible risk decisions.
Machine Learning Operations
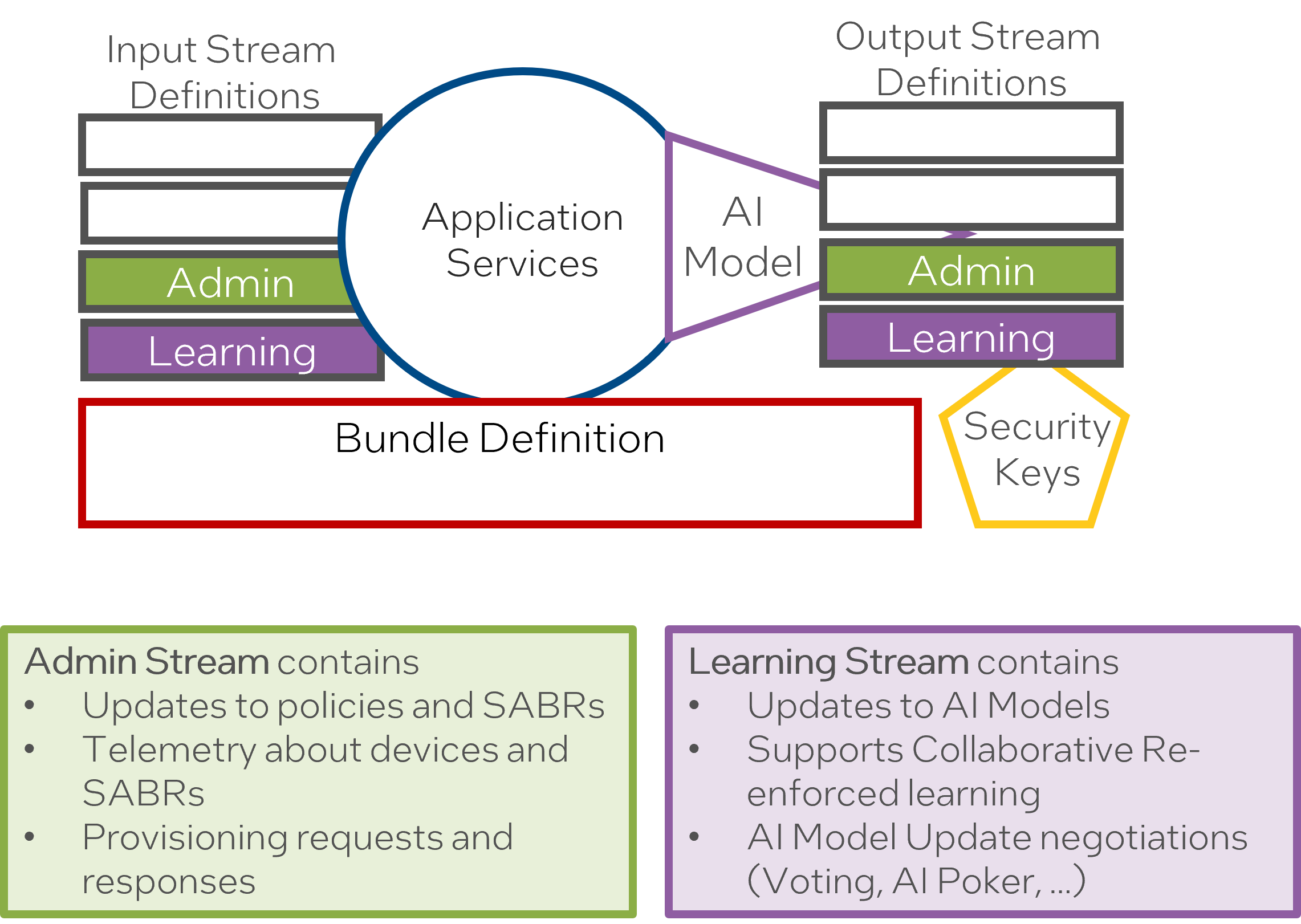
“SABRs are monitored through the Admin Stream through telemetry.”: SABR instances are persistently observed using the Admin Stream with the support of telemetry data. Telemetry involves collecting data from remote or inaccessible points and transmitting it to an IT system for subsequent monitoring. This step enhances the system’s capability to respond swiftly and accurately to changes and potential issues.
“The DevSecOps process ensures that SABRS are encrypted before deployment.”: This indicates the application of encryption to the SABRs before deployment, as part of the DevSecOps procedures. Encryption helps secure data by converting it into a form that can only be understood by authorized parties, further safeguarding sensitive information from unauthorized access.
“SABR Dashboard and “Admin Stream” give visibility into SABR and device health.”: The SABR Dashboard and the Admin Stream are utilized for real-time visibility into the health and performance of the SABR instances and their respective devices. This affords administrators the opportunity to proactively safeguard the system’s optimal performance and effectively respond to any potential issues.
“Integration with a Risk Management Framework.”: This statement implies that the SABR system incorporates a Risk Management Framework. A Risk Management Framework is a collection of processes that aid in identifying, analyzing, evaluating, and responding to organizational risk to optimize decision-making. The integration adds a layer of systemic risk evaluation and management to the system’s processes, contributing to improved security and performance management.
Resilient and Tolerant DDIL
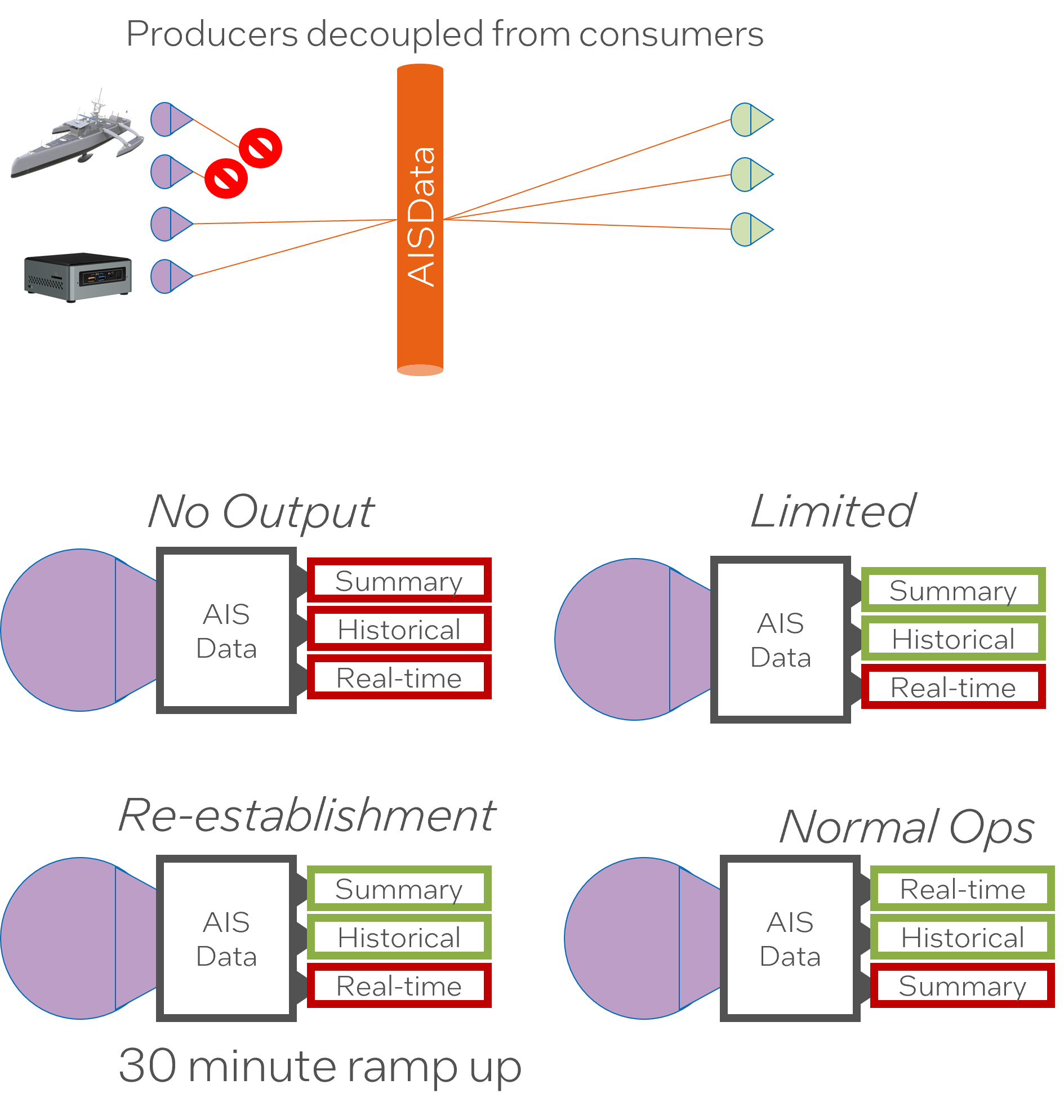
“SABRs are decoupled and not dependent on each other.”: This implies that each SABR operates independently of the others. Decoupling allows each SABR to function separately, improving the system’s flexibility and reducing the impact of any single SABR’s failure on the entire system.
“SABRs can operate on different volumes of data.”: This provides insight into the system’s adaptability and scalability. Particularly, it suggests that the SABRs are capable of handling and operating on varying data volumes, ensuring smooth performance irrespective of the size of data being processed.
“Minimal data still provides value.”: This indicates the system’s ability to extract valuable insights even from minimal sets of data. This would allow for efficient data utilization, ensuring that no data, regardless of its quantity, is wasted or unused.
“The policies enable the activation and deactivation of channels depending on the environment.”: This reveals the existence of policies that manage channel activation and deactivation based on environmental circumstances. This system feature contributes to adaptability, enabling channel operations to be modified as needed to fit specific contexts.
“When network connectivity is restored, the policies give priority to the movement of data through channels.”: This indicates that once network connectivity resumes after a disruption, data movement via the channels is prioritized. Such policies can help in ensuring continuity and minimizing the impact of interruptions on data transfer activities.
Solution
To enable a future-proof and expandable system, it is essential to understand how different parts of the system relate to each other and establish isolation layers (through standard interfaces or abstractions). This isolation allows the various subsystems in the solution to “grow” in parallel with minimal effect on each other. The SABR architecture should not be the only data management architecture utilized in the system. Leveraging common architectural elements is critical to developing a resilient and cost effective system. With the end goal in mind and the establishment of interfaces between the sub-systems, new features for hardware or software can be added progressively toward the utopian end state.
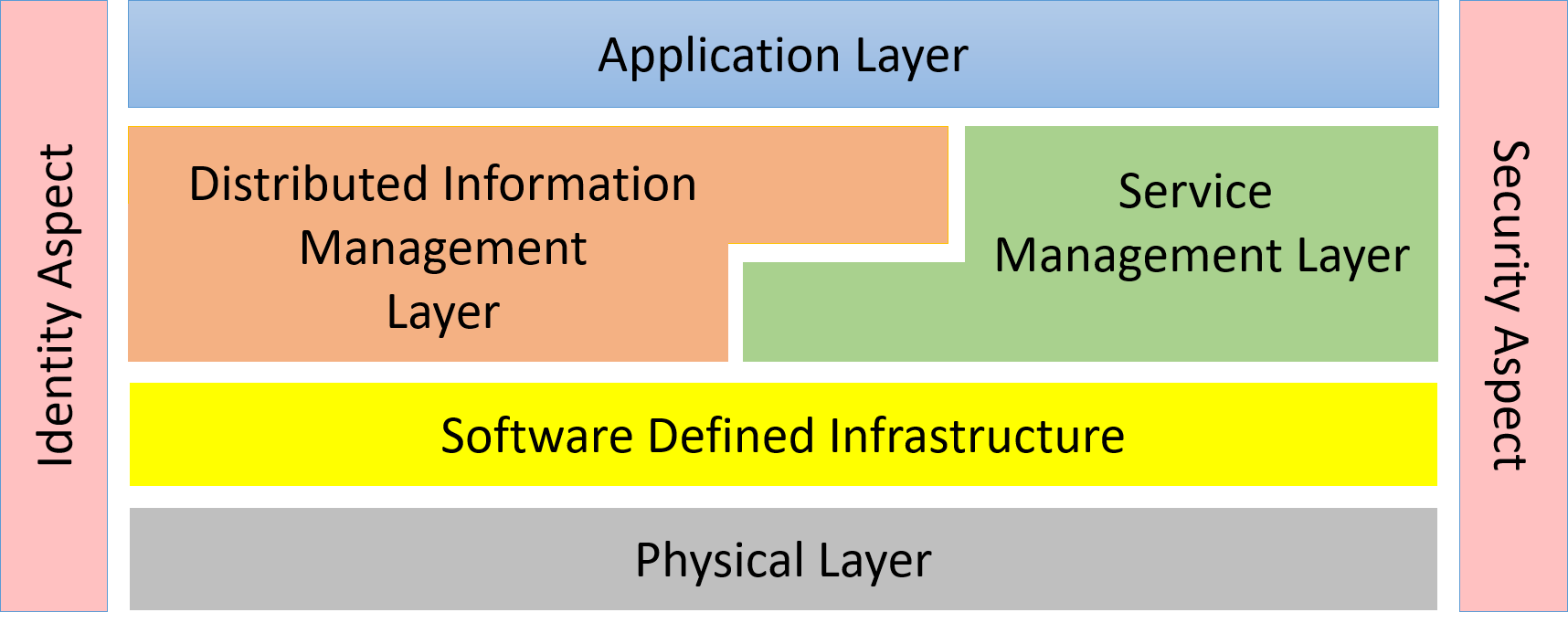
This diagram shows how the different subsystems fit together. A quick understanding of each layer will expose the responsibilities of each layer.
- Application Layer – Responsible for the management (development, test and deployment) of applications in the solution.
- Distributed Information Management Layer – Responsible for the management (curation, governance, lifecycle management, and tagging) of data across a heterogeneous infrastructure (Cloud, Data Center, Edge and Client).
- Service Management Layer – Responsible for the deploying, monitoring, and provisioning of services (containers) in the solution.
- Software Defined Infrastructure – Responsible for the management (deploying, monitoring and provisioning) of infrastructure (Compute, Storage, Network, and Accelerators) in the solution.
- Physical Layer – Responsible for the command, control and monitoring of the physical devices in the solution.
- Security Aspect – Gives a common security model across the subsystems of the solution.
- Identity Aspect – Give the ability to uniquely identify and attest identity of users, hardware, applications, services, and virtual resources.
SABR Logical Architecture
The SABR architecture is an instantiation of the Edgemere Architecture and maps directly on top of the Edgemere Architecture. Not all elements of Edgemere are required for the SABR architecture. Assumptions are made that an SDI and Physical layer are already established in the solution. The following diagram shows the subsystem specific to the SABR architecture.
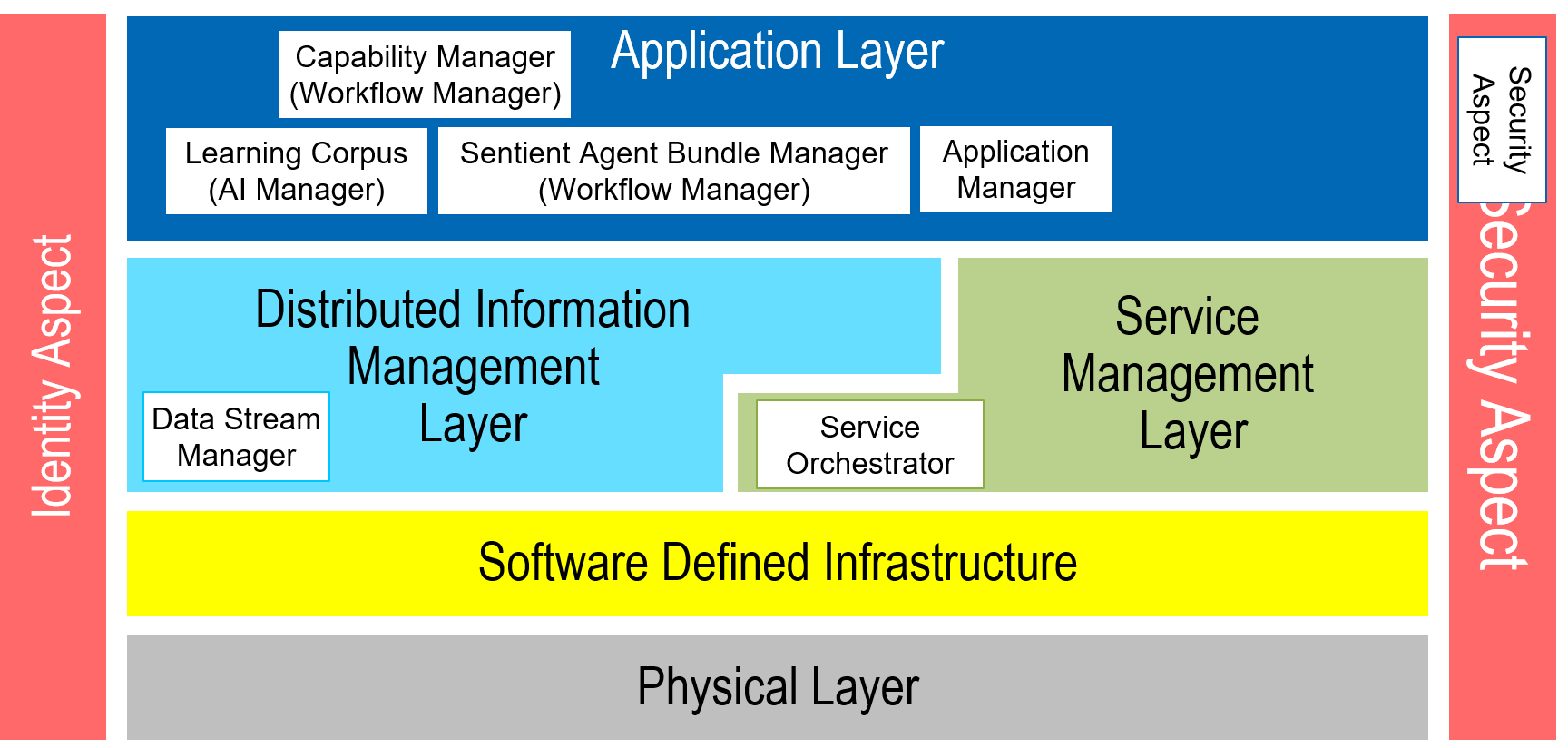
- Application Manager – Responsible for the management (development, test and deployment) of applications in the solution.
- Capability Manager – Responsible for the deployment and management of capabilities in the ecosystem, including the deployments of multiple SABRs.
- Data Stream Manager – Responsible for the deploying, monitoring, and provisioning of data streams in the ecosystem.
- Learning Corpus – Responsible for the management of AI learning algorithms, their updates, and deployments.
- Security Aspect – Gives a common security model across the subsystems of the solution.
- Sentient Agent Bundle Manager – Gives the ability to bundle data streams, ai algorithms and operating in a heterogeneous environment.
- Service Orchestrator – Responsible for the deployment and management of services in the ecosystem.
Benefits
One of the benefits of this architecture is applications can be developed in the data center and in a similar environment as what runs on the edge. User acceptance, unit level, and burn-in testing can all be performed on systems in the data center and then deployed in the field without variability in quality and operating. Because the Physical Layer is abstracted from the applications, the applications freely move between the different hardware. This easily lends itself to the portability of applications and capabilities and decreases the time to develop, test, and deploy applications and services. Putting in place a modern DevOps stack in the Application Layer can dramatically increase the deployment velocity. This also decreases the need for Digital Twin infrastructure and operations. Because the hardware is shared between the Data Centers and On ship servers, the need to build a complete digital twin is no longer needed. Only specialized hardware/application systems would need to be “mimicked (ed)” for digital twin.
Deployment Design Patterns
This solution is deployed using service stack design pattern where a stack of services collaborate together to deliver functionality to the system. An extendtion of this design pattern to aggregated service stacks allow the for isolation of different parts of the system to occur while maintaining consistency in security and system policies.
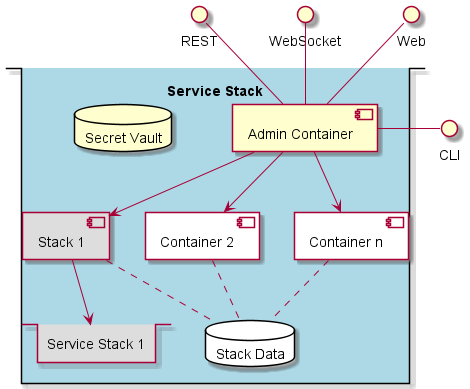
Each aggregated service stack has an administration side-car container that manages and monitors the stack. This micro service design pattern is shown in the diagram below. A nodejs app is used to implement the admin sidecar in the system. Each service stack has a CLI, REST, and Web Interface exposed through this nodejs application. Additionally, the system can handle events through a WebSocket interface. The nodejs application will interface with the microservices and can monitor and drive workflows through the mesh of microservices.
The solution can be deployed in different environments. The standard environments in the architecture are local, dev, test, and prod. These environments fit into the typical DevOps pipelines that exist in the industry. Additional deployment environments can be added to fit the needs of the user.
Physical Design Pattern
The Sentient Agent Bundle Resources architecture is physically laid out using a microservice architecture on a hybrid multi-cloud infrastructure. This includes running in the cloud, in the data center, and on edge devices. All capabilities of the system are deployed through micro-services and require a container orchestrator to deploy containers.
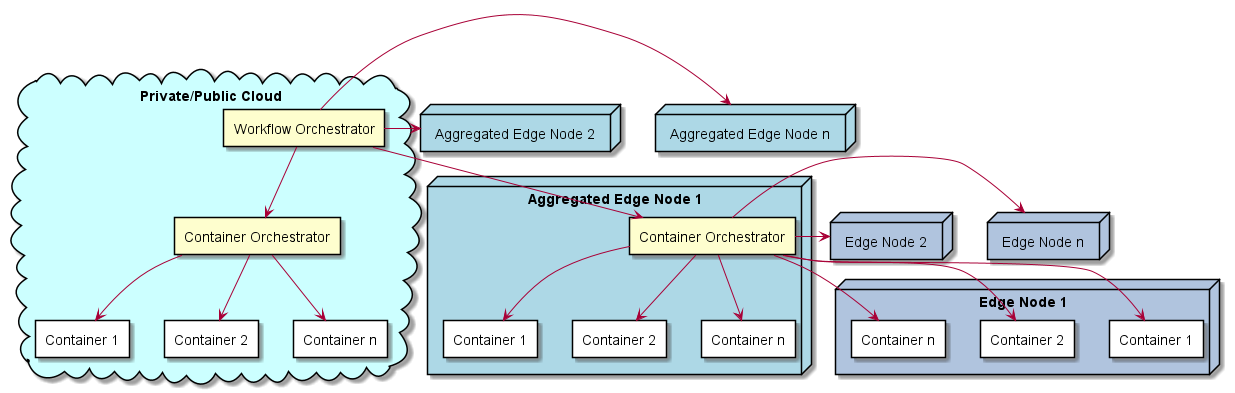
All the microservices communicate with the administrative app through a REST. WebSocket and Apache Pulsar interface. A CLI, REST, WebSocket, and Web interface is available for external systems or users to interact with the system. All communications are encrypted and decryption keys are shared in the secret encrypted vault in the SABR container. Each subsystem in the architecture uses an aggregated service/stack pattern that allows for the elasticity of services based on the workloads, capacity, and business rules established for the solution. See each subsystem for more information on the individual stacks and their services.
Use Cases
The following are the use cases of the Sentient Agent Bundle Resources subsystem. Each use case has primary and secondary scenarios that are elaborated in the use case descriptions.
- Manage AI Model
- Manage Capabilities
- Manage Policies
- Manage Security
- Provide Digital Assistance
- Provide Mission Insight
- Ships

Users
The following are the actors of the Sentient Agent Bundle Resources subsystem. This can include people, other subsystems inside the solution and even external subsystems.
- DataEngineer
- DataScientist
- DataAnalyst
- DevOpsEngineer
- ITOperations
- SecurityOperator
- TacticalOperator

Interface
The subsystem has a REST, CLI, WebSocket, and Web interface. Use Cases and Scenarios can use any or all of the interfaces to perform the work that needs to be completed. The following diagram shows how users interact with the system.

- sabr streampolicy activate
- sabr streampolicy create
- sabr streampolicy deactivate
- sabr streampolicy update
- sabr application create
- sabr bundle build
- sabr bundle create
- sabr capability create
- sabr environment create
- sabr pulsar streams
- sabr pulsar topic
- sabr pulsar topics
- sabr sabundle build
- sabr streampolicy create
Logical Artifacts
The Data Model for the Sentient Agent Bundle Resources subsystem shows how the different objects and classes of object interact and their structure.

Sub Packages
The Sentient Agent Bundle Resources subsystem has sub packages as well. These subsystems are logical components to better organize the architecture and make it easier to analyze, understand, design, and implement.
- Application Management Layer
- Common Physical Layer
- Distributed Information Management Layer
- Identity Aspect
- Security Aspect
- Service Management Layer
- Software Defined Infrastructure

Classes
The following are the classes in the data model of the Sentient Agent Bundle Resources subsystem.
Deployment Architecture
This subsystem is deployed using micro-services as shown in the diagram below. The ‘micro’ module is used to implement the micro-services in the system. The subsystem also has an CLI, REST and Web Interface exposed through a nodejs application. The nodejs application will interface with the micro-services and can monitor and drive work-flows through the mesh of micro-services. The deployment of the subsystem is dependent on the environment it is deployed. This subsystem has the following environments:
Physical Architecture
The Sentient Agent Bundle Resources subsystem is physically laid out on a hybrid cloud infrastructure. Each microservice belongs to a secure micro-segmented network. All of the micro-services communicate to each other and the main app through a REST interface. A Command Line Interface (CLI), REST or Web User interface for the app is how other subsystems or actors interact. Requests are forwarded to micro-services through the REST interface of each micro-service. The subsystem has the a unique layout based on the environment the physical space. The following are the environments for this subsystems.
Micro-Services
These are the micro-services for the subsystem. The combination of the micro-services help implement the subsystem’s logic.
local
Detail information for the local environment can be found here
Services in the local environment
- web : sabr_web
- pulsar : sabr_pulsar:standalone
- doc : sabr_doc
dev
Detail information for the dev environment can be found here
Services in the dev environment
- aml : sabr_aml
- cpl : sabr_cpl
- diml : sabr_diml
- sa : sabr_sa
- sml : sabr_sml
- sdi : sabr_sdi
- ia : sabr_ia
- doc : sabr_doc
test
Detail information for the test environment can be found here
Services in the test environment
- aml : sabr_aml
- cpl : sabr_cpl
- diml : sabr_diml
- sa : sabr_sa
- sml : sabr_sml
- sdi : sabr_sdi
- ia : sabr_ia
- doc : sabr_doc
prod
Detail information for the prod environment can be found here
Services in the prod environment
- aml : sabr_aml
- cpl : sabr_cpl
- diml : sabr_diml
- sa : sabr_sa
- sml : sabr_sml
- sdi : sabr_sdi
- ia : sabr_ia
- doc : sabr_doc
Activities and Flows
The Sentient Agent Bundle Resources subsystem provides the following activities and flows that help satisfy the use cases and scenarios of the subsystem.
Messages Sent
| Event | Description | Emitter | |——-|————-|———|
Interface Details
The Sentient Agent Bundle Resources subsystem has a well defined interface. This interface can be accessed using a command line interface (CLI), REST interface, and Web user interface. This interface is how all other subsystems and actors can access the system.
Action sabr streampolicy activate
- REST - /sabr/streampolicy activate?attr1=string
- bin - sabr streampolicy activate –attr1 string
- js - .sabr.streampolicy activate({ attr1:string })
Description
Description of the action
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| attr1 | string | false | Description for the parameter |
Action sabr streampolicy create
- REST - /sabr/streampolicy create?attr1=string
- bin - sabr streampolicy create –attr1 string
- js - .sabr.streampolicy create({ attr1:string })
Description
Description of the action
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| attr1 | string | false | Description for the parameter |
Action sabr streampolicy deactivate
- REST - /sabr/streampolicy deactivate?attr1=string
- bin - sabr streampolicy deactivate –attr1 string
- js - .sabr.streampolicy deactivate({ attr1:string })
Description
Description of the action
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| attr1 | string | false | Description for the parameter |
Action sabr streampolicy update
- REST - /sabr/streampolicy update?attr1=string
- bin - sabr streampolicy update –attr1 string
- js - .sabr.streampolicy update({ attr1:string })
Description
Description of the action
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| attr1 | string | false | Description for the parameter |
Action sabr application create
- REST - /sabr/application/create?name=string&file=file
- bin - sabr application create –name string –file file
- js - .sabr.application.create({ name:string,file:file })
Description
Description of the action
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| name | string | false | Name of the apaplication to Create |
| file | file | false | File of the application definition |
Action sabr bundle build
- REST - /sabr/bundle/build?dir=string&recurse=boolean&output=string
- bin - sabr bundle build –dir string –recurse boolean –output string
- js - .sabr.bundle.build({ dir:string,recurse:boolean,output:string })
Description
Build a SAB bundle for the directory specified.
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| dir | string | true | Directory to perform the build. |
| recurse | boolean | false | Recursive build from the directory down. |
| output | string | false | Output file for the bundle. |
Action sabr bundle create
- REST - /sabr/bundle/create?name=string&file=file
- bin - sabr bundle create –name string –file file
- js - .sabr.bundle.create({ name:string,file:file })
Description
Description of the action
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| name | string | false | Name of the apaplication to Create |
| file | file | false | File of the application definition |
Action sabr capability create
- REST - /sabr/capability/create?name=string&file=file
- bin - sabr capability create –name string –file file
- js - .sabr.capability.create({ name:string,file:file })
Description
Create a capability in the system.
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| name | string | true | Name of Capability |
| file | file | true | Filename of the definition |
Action sabr environment create
- REST - /sabr/environment/create?name=string&file=file
- bin - sabr environment create –name string –file file
- js - .sabr.environment.create({ name:string,file:file })
Description
Create Environment for the system
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| name | string | false | Name of the environment to Create |
| file | file | false | File of the environment definition |
Action sabr pulsar streams
- REST - /sabr/pulsar/streams?id=string
- bin - sabr pulsar streams –id string
- js - .sabr.pulsar.streams({ id:string })
Description
Return the topics in the pulsar configuration
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| id | string | true | ID of the topic. should be fully qualified |
Action sabr pulsar topic
- REST - /sabr/pulsar/topic?id=string
- bin - sabr pulsar topic –id string
- js - .sabr.pulsar.topic({ id:string })
Description
Return the topics in the pulsar configuration
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| id | string | true | ID of the topic. should be fully qualified |
Action sabr pulsar topics
- REST - /sabr/pulsar/topics?
- bin - sabr pulsar topics
- js - .sabr.pulsar.topics({ })
Description
Return the topics in the pulsar configuration
Parameters
No parameters
Action sabr sabundle build
- REST - /sabr/sabundle/build?attr1=string
- bin - sabr sabundle build –attr1 string
- js - .sabr.sabundle.build({ attr1:string })
Description
Description of the action
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| attr1 | string | false | Description for the parameter |
Action sabr streampolicy create
- REST - /sabr/streampolicy/create?name=string&file=file
- bin - sabr streampolicy create –name string –file file
- js - .sabr.streampolicy.create({ name:string,file:file })
Description
Create a stream policy for the system
Parameters
| Name | Type | Required | Description |
|---|---|---|---|
| name | string | false | Name of the policy to Create |
| file | file | false | File of the policy definition |